



Data is more than just a byproduct of operations – it is what drives them. Organizations are moving beyond static snapshots of past performance and are now demanding systems that can process, analyze, and deliver actionable insights in real-time. This need is particularly urgent in dynamic sectors like finance and healthcare, where timely information can drive critical decisions.
The value of near real-time data processing cannot be overemphasized, whether it is to produce reports instantly, feed the latest data to AI and machine learning models, or make decisions based on the latest information. Studies have revealed that 78% of executives say they struggle to use their data to its full potential for decision-making.
I and Mukesh have contributed to projects where real-time data is crucial. We have developed a scalable solution for building such a pipeline using Debezium’s change data capture (CDC) technology in conjunction with Kafka Connect based on our experience. In this blog, we delve into the details of this solution, explaining its implementation and benefits.
Background and challenges in legacy system migration
When businesses transition from legacy systems to new data processing frameworks, many significant challenges arise. These challenges often hinder the seamless, real-time data integration and processing crucial for modern decision-making and reporting. The most common challenges are listed below:
- High Database Load: Directly querying operational databases for reporting can slow down transaction processing and affect system performance.
- Lack of Centralized Data: Without a unified data lake, data remains siloed, complicating reporting, AI/ML model building, and data processing.
- Delayed Data Access: Traditional ETL processes often lead to delays in data availability for reporting and analytics.
- Real-Time Reporting: Organizations require near-real-time data access to make timely decisions, especially for tools like Power BI
Proposed solution architecture: Building a scalable, real-time data pipeline
To address these challenges, the proposed design uses Change Data Capture (CDC) techniques and an event-driven architecture to create a centralized, near real-time data pipeline. The core components of the solution are:
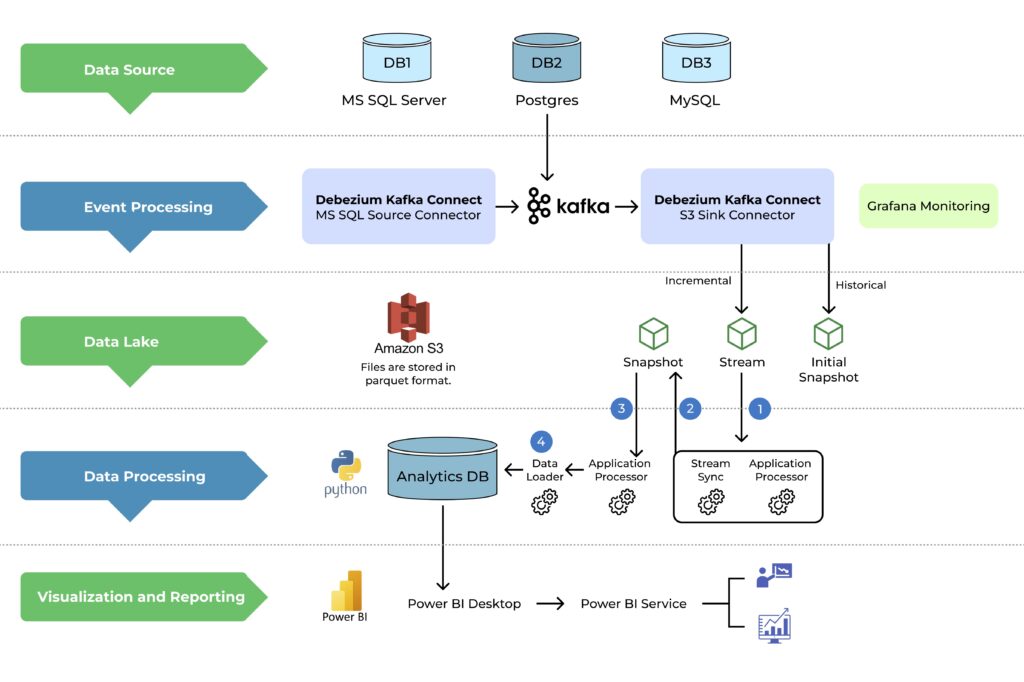
Debezium for change data capture (CDC)
- Debezium, an open-source CDC platform, captures real-time changes from databases (such as MS SQL and Postgres) without overwhelming the database.
- It tracks inserts, updates, and deletes, allowing for incremental data processing.
Kafka for event streaming
- Apache Kafka serves as the backbone for event streaming, ensuring reliable, real-time data flow from databases to the processing layer.
- Data streams are processed in real-time, reducing latency between data generation and reporting.
Amazon S3 as a centralized data lake
- Data from Kafka is ingested into Amazon S3, where it is stored in Parquet format for efficient querying and long-term storage.
- S3 serves as a centralized repository that holds snapshots and historical data for future processing.
Data processing with an analytics database
- An Analytics Database (such as Postgres) aggregates and synchronizes the incoming data streams for consistency.
- Components such as Stream Aggregator and Stream Sync are used to ensure the latest changes are reflected in the database, allowing for consistent reporting and analysis.
Power BI integration for real-time reporting
- The processed data from the Analytics Database is fed into Power BI, where stakeholders can generate real-time reports.
- Power BI enables users to visualize data, build dashboards, and share insights easily across teams.
Monitoring and maintenance with Grafana
- A monitoring tool such as Grafana tracks the health and performance of the entire pipeline. This ensures quick detection and resolution of issues, maintaining seamless operations.
Implementation steps for a seamless data pipeline
Step 1: Set up Debezium and Kafka setup
Configure Debezium to capture CDC from source databases and stream the data to Kafka.
Step 2: Establish the data lake
Set up an S3 bucket to store data in Parquet format and configure the Kafka S3 Sink Connector to push data to S3.
Step 3: Build the data processing pipeline
Set up the Analytics DB and implement custom components like Stream Aggregator, Stream Sync, and Data Loader for efficient data processing.
Step 4: Integrate power BI
Connect Power BI to the Analytics DB for real-time reporting and analytics.
Step 5: Monitor the system
Use Grafana to monitor the pipeline and ensure the system is stable under different load conditions.
Step 6: Production deployment
Deploy the pipeline in the production environment and continuously monitor and optimize the performance.
Key Benefits of the architecture
Reduced Database Load: By using Debezium’s CDC approach, the solution minimizes the load on operational databases, improving their performance.
Centralized Data Lake: A centralized data lake simplifies data management, enabling advanced reporting, AI/ML model training, and data analytics.
Real-Time Reporting: The pipeline allows for near-real-time data processing, which provides timely insights for decision-making.
Scalability: The architecture is designed to handle growing data volumes, ensuring future scalability without performance degradation.
AI/ML Model Support: With clean, consistent, and centralized data, the pipeline supports advanced analytics and AI/ML model training, enhancing predictive capabilities.
Conclusion
Building a near-real-time data pipeline is essential for organizations looking to modernize their data infrastructure and enhance reporting capabilities. By leveraging Debezium, Kafka, and Amazon S3, businesses can create a scalable, efficient, and real-time data processing system that meets the needs of today’s fast-paced, data-driven environments. Whether for reporting or AI/ML tasks, this architecture provides the foundation for a more efficient and responsive data ecosystem.









