

Recently, NLP has made remarkable advancements with models like GPT and BERT. However, the static data these models are trained on make much of the answer either outdated or generalized. This makes the models unfit for domains demanding precise and up-to-date data. It is here that Retrieval-Augmented Generation, or RAG, comes in.
Users asking for particular information is not so uncommon. While building chatbots, I have seen people looking for specific data from technical documents. I have used RAG to solve these problem and yes, it can transform these chatbots by generating dynamic, contextual, and more relevant, up-to-date responses by directly accessing and understanding content from these documents.
Since it has proven to be so beneficial to me, I wanted to share it with other developers. In this article, I will discuss how to implement RAG pipeline using Spring AI and its challenges, along with some practical tips.
What is RAG pipeline?
With a RAG pipeline, the accuracy and quality of responses of AI models increase. RAG pipelines deliver this by merging the response retrieval and generation processes.
To find the most relevant information based on the user’s query, the system first searches a vast database or knowledge base, such as the Internet, articles, or a custom knowledge base.
After that, it generates a final answer using a language model (such as GPT or T5). But this time the model incorporates the information that was obtained to make the answer more accurate and informative.
How to implement RAG pipeline using Spring AI
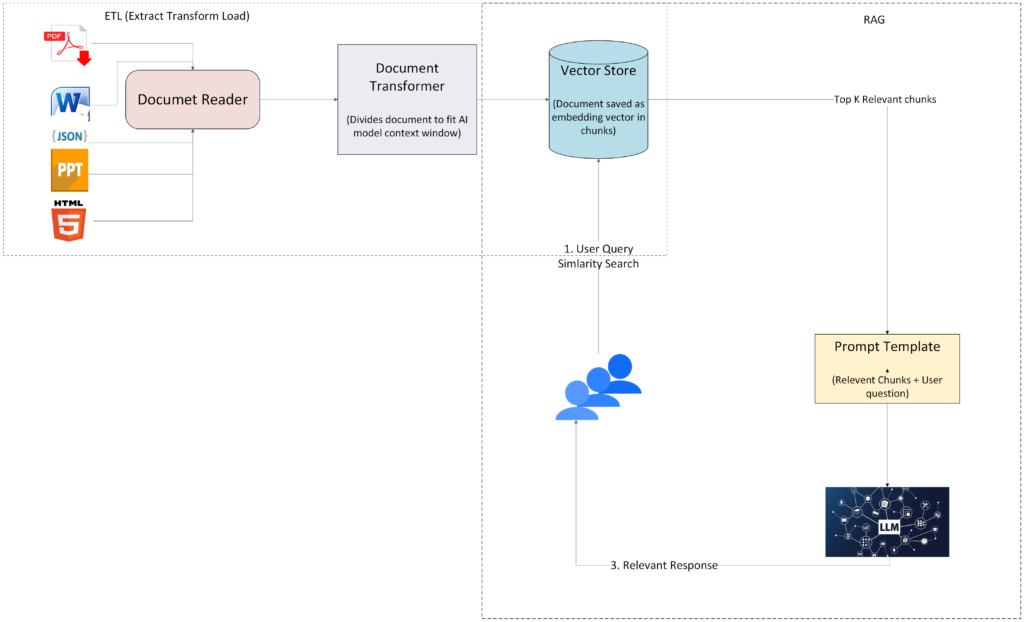
The Retrieval-Augmented Generation (RAG) pipeline combines external knowledge retrieval with powerful language models (LLMs) to enhance their responses.
It’s made up of two key modules: the ETL (Extract, Transform, Load) module and the RAG (Retrieval-Augmented Generation) module. Together, these modules allow for efficient document processing and enhanced AI-driven responses. Let’s break them down:
The ETL module: Extract, transform, load
The ETL module is the first step in preparing documents for the RAG pipeline. It involves three key phases: Extract, Transform, and Load.
Document reader (Extract)
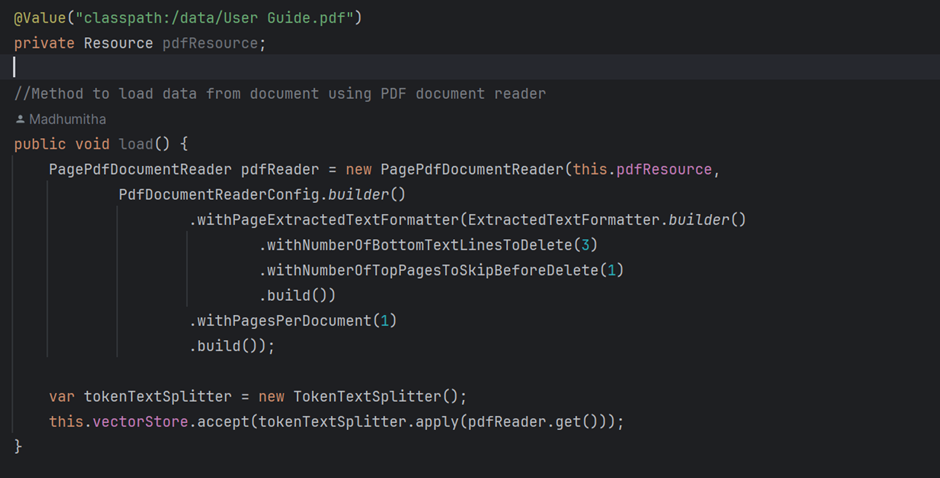
The first phase is the Extract step, where documents are read and parsed. Whether they come from PDFs, Word documents, PowerPoint presentations (PPT), or web pages, the content is extracted and converted into a Document object, which is essentially a structured format that holds the document’s content along with metadata.
Each document is tagged with basic information, like the source (e.g., the file name), and can also include custom metadata, such as a file version or document author. For example, with a PDF, each paragraph or page can be treated as a separate document object, parsed with tools like ParagraphPdfDocumentReader or PagePdfDocumentReader.
Transformers (Transform)
Next, the Transform step kicks in. Here, documents are broken down into manageable chunks. Since most AI models have a fixed context window (i.e., a limit to how much text they can process at once), it’s important to split documents to fit within this window. This is where tools like the TextSplitter and TokenTestSplitter come into play. They divide a document into smaller sections based on context size or token count.
Additionally, tools like KeywordMetadataEnricher and SummaryMetadataEnricher can add rich metadata, such as keywords or summaries of each chunk, to further enhance the document’s value during the RAG process.
Loading data into a vector database (Load)
Finally, in the Load phase, the transformed document chunks are stored in a vector database. Unlike traditional databases, which store data as text or records, vector databases store documents as embedding vectors—numerical representations of the document’s content.
Instead of relying on exact text matches, a similarity search is conducted within the vector database. When a query is posed, the vector database compares the user’s input to the stored vectors and retrieves the most similar documents based on these embeddings.
The RAG module: Retrieval and generation
Now, let’s look at how the RAG module kicks in. This part of the process involves retrieving relevant information from the vector database and using it to generate a highly accurate response.
Step 1: Loading data into the vector database
As mentioned earlier, the first step in the RAG process is to load documents into the vector database. Once documents are embedded and stored as vectors, they become accessible for similarity searches. This is the foundation upon which the RAG module operates.
Step 2: Retrieving relevant documents
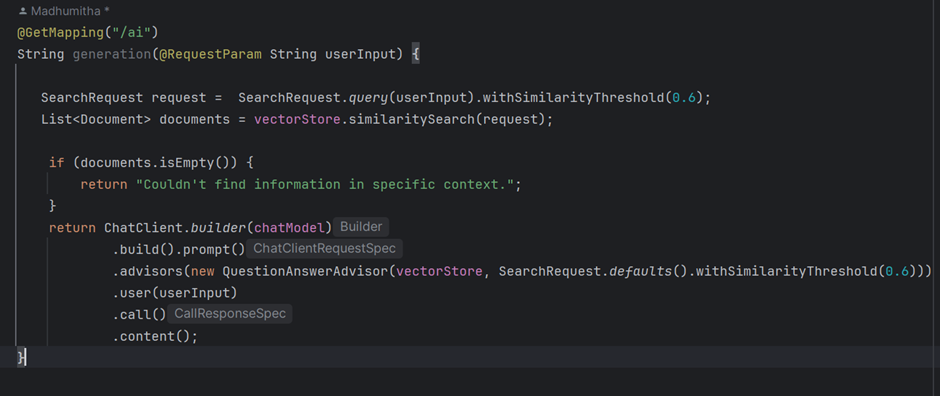
When a user asks a question, the system doesn’t rely solely on the model’s internal knowledge. Instead, the query is converted into an embedding vector, which is then compared against the vectors stored in the vector database. The most relevant documents based on similarity are retrieved and used as context for answering the user’s question.
Step 3: Passing context to the AI model
Once the relevant documents are retrieved, they are sent to the AI model alongside the user’s query. The AI model uses this context—real, up-to-date information from the documents—to generate a more precise, relevant response. This ensures that the answer is grounded in external data, offering more accurate and informed results than if the AI had only relied on its pre-existing knowledge.
Reference GitHub Repository – https://github.com/Talentica/RAG-SpringAI.git
Key tips for using RAG:
Tip 1: Ensure all information within the documents is correct and up to date.
Tip 2: When a document is modified, re-generate its embedding and update its representation in the vector database.
Challenges I faced
One of the biggest challenges I encountered was hallucination, when the language model generated incorrect or meaningless answers due to irrelevant or incomplete context. To fix this, I set a similarity threshold of 0.6 for document retrieval. If no relevant documents met the threshold, the system displayed a default message instead of passing incomplete data to the language model.
Another challenge was ensuring data privacy while working with sensitive documents. To fix this, I replaced sensitive details with placeholders during the transformation process to prevent potential data leaks.
Conclusion
RAG is a powerful technique that combines information retrieval with language generation to improve AI models. Using Spring AI, I implemented a RAG pipeline and thereby improved the accuracy, relevance, and contextuality of chatbot responses.
This approach can potentially transform not just chatbots but any AI system that needs dynamic, real-time access to external knowledge. If you need to bridge static knowledge with dynamic user needs, a RAG pipeline might just be the answer you are looking for.









