


https://github.com/priyakartalentica/postgresqlPartitioningTable.git
Introduction
Imagine a dump yard full of scrapped cars. If you have to find a particular Ford Mustang there, you might end up spending days before locating the right one. Now, think of a trip to the Walmart. If you have to find a needle there, it will hardly take a few minutes. Why so? The right answer is proper partitioning. Such segregation is a must for effective operation.
The same is true for data and database. High volume of data leads to slower read and write. Read and write status improves when you implement partitioning well.

What is Partitioning?
Partitioning is dividing the large grown tables into physical pieces. So given the situation, the table could grow either horizontally or vertically.
When to Partition a table
The precise point that ensures benefits from partitioning depends on the application design. General strategies to take partitioning decision are as follows:
- The size of the table has grown huge.
- As a rule of thumb, the size of the table should exceed the database server’s physical memory
Types of Partitioning
- Vertical Partitioning
If your table has grown fat, i.e., there are too many columns which might be a major reason for slower writes, then you have to think whether the columns are needed in one single table or can be normalized. Such a partitioning process is also known as “row splitting”.
- Horizontal Partitioning
If your table has grown tall with a huge number of records, it will consume high table scan time to fetch records. For such cases, indexing might be a good solution. Indexing stores pointers to unique elements so that you can quickly reach the data. Just like the index section of a book where you can search the keyword for the page number. It speeds up the process of getting hands on the content you want. But with a growing number of records, your operation slows down. Consider a hypothetical situation where the Glossary (Index) grows so huge that it starts to consume more of your processing time. A possible way out would be dividing the book into logical volumes. Similarly, when your table grows massive, think of sharding, which is a part of the horizontal partitioning strategy.
It creates replicas of the schema and then divides the data stored in each partition based on keys. This requires the load to be distributed and spaced evenly across shards based on data-access patterns and space considerations. Horizontal partitioning requires the classification of different rows into different tables. It can be further classified as follow:
If you have user data like Facebook or LinkedIn, you might prefer to partition it based on regions or a list of cities in a region which is a List-based partitioning strategy.
In the case of a table storing sales data, you can partition it “month-wise,” which is Range-based partitioning. Range-based partitioning maps the data to different partitions based on ranges of values of the partitioning key that you establish for each partition.
Benefits of Partitioning
-
- You can radically improve the query performance by storing frequently accessed rows or groups of rows in similar partitions or a small number of partitions.
- Partitioning can improve the performance by using a sequential scan of a partition instead of using an index and random access reads scattered across the whole table in certain scenarios when queries or updates access a large percentage of a single partition.
- If you are serving use-cases where Bulk loads and deletes are required (based on partitioning criteria), it can be efficiently done by adding or removing partitions.
- Less-used data can be migrated to cheaper and slower storage media thus saving cost.
Problem Statement / POC for Horizontal List based partitioning
Recently, we were in a situation where the reads and writes were extremely slow for a PostgreSQL DB. On examining, we found that the table had around 10 million rows. We replicated the scenario and carried out a benchmarking exercise to see how each use-case behaves, given each table has 10 million records. Following are the list of use-cases we tested for:
-
- Normal table without indexes
- Table will Indexes
- Partitioned table without Indexes
Steps to Carry out the Benchmarking Exercise
-
- Started a docker instance to have PostgreSQL and pgAdmin running. docker-compose.yml file is present in the GitHub repo to spawn a similar instance for you.
- We created 3 tables (Normal, Indexed, and Partitioned table). Each with 10 million records. Scripts to create the tables and insert 10 million records are present in the GitHub repo link mentioned below.
- Each table had the following fields:
- item_id
- item_name
- store_id
- category_id
- country_id
- retailor_id
- score
- Data Distribution in Table: 10 million items were evenly distributed across 10 categories, 50 stores, and 20 retailers across 5 countries.
- Background of the client – Our client had a chain of stores wherein customers can ask regarding items in a store inventory.
- Partitioning strategy – We observed that the data was a bit evenly distributed across stores. Even customers visiting the stores would query the data for a particular store. So, in our scenario, the store id was considered as the partition key.
- Ran the following queries against each table using pgAdmin. List of Queries are as follows:
-
- select avg(score) where store_id=?
- insert 100 records for a store_id
- update 100 records for a store_id
- select avg(score) where category_id=?
- insert 1000 records for a store_id
- update 1000 records for a store_id
- insert 10000 records for a store_id
-
update 10000 records for a store_idBenchmarking Observations
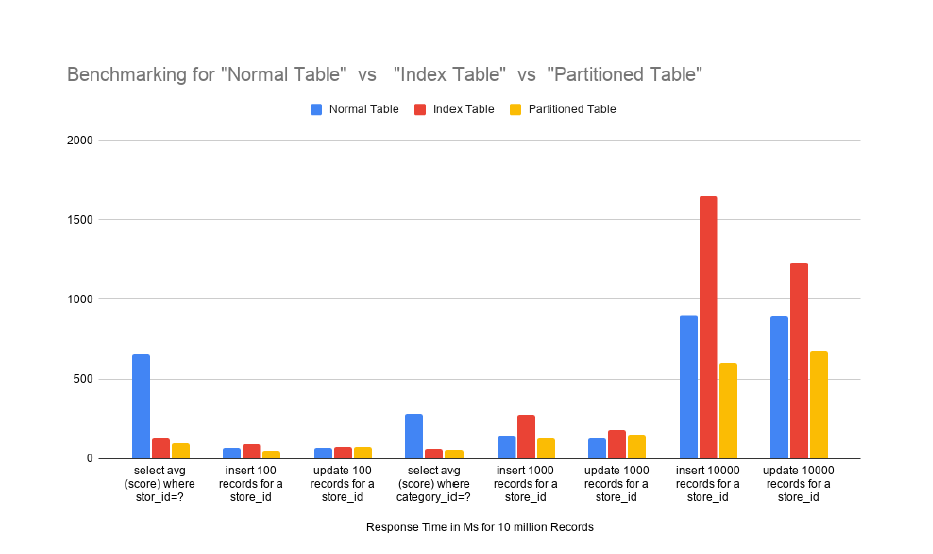
From the Graph and the reading in the table it is very clear that Partitioned tables functioned better than indexed tables under higher data loads. And it is an eye opening observation that indexing can slow down your system when the data load increased and might trigger full memory scan itself.
Reads Operations
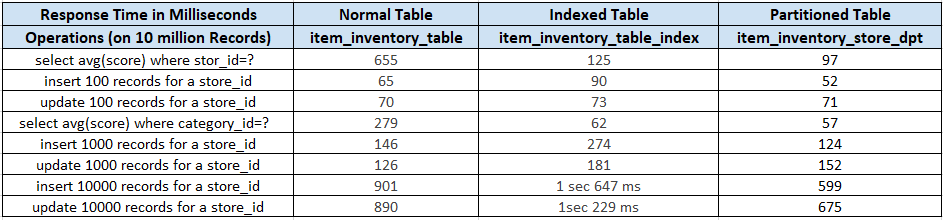
For instance, when every store has around 20K records and every category has around 2 Lakh records, performing an aggregate function table takes 655ms and the indexed table takes 125ms. At the same time, a partitioned table outperforms others by completing the task in 97ms.
While performing an aggregate function for 2 lakh records, a normal table takes 279 ms and the indexed table fetches result in 62 ms. There, the partition table scores marginally well by providing the output within 57ms. The numbers will grow in sync with the data load.
So in terms of reading, opting for a Partition table will be a good decision with the given underlying scenario, followed by Indexing, and the least preferred will be the normal table without indexes in terms of Reading data.
Inserts and Updates (Write Operations)
We carried out the write operation, which consists of inserts and updates in a batch of 100, 1000, and 10000 items. Each insert/update was performed and stored for random categories having random scores so that PostgreSQL doesn’t introduce its optimizations.
After carrying out the inserts, we observed that the normal table is performing better than indexed tables and partitioning outperformed with lower response time for bulk or higher load. It resulted in faster writes as the partitioning was done based on the store. We realized that all the data needs to be written for a single store, i.e., in one partitioning and without the overhead of maintaining indexes.
In short, partitioning performed way better than the indexed table in terms of reads and writes with the growing data load.
Conclusion
Partitioning divides logical data elements into multiple entities to improve performance, availability, and maintainability. You can make the decision based on the application type. Also, go for it if your tables grow too large and none of the optimization techniques work anymore. Under heavy data load, partitioning will improve the read response time and function better in terms of writes.
Github Link for the scripts
https://github.com/priyakartalentica/postgresqlPartitioningTable
References:
https://dzone.com/articles/how-to-handle-huge-database-tables
https://www.postgresql.org/docs/current/ddl-partitioning.html








