


Kafka Introduction
Before understand the Kafka bench-marking, let me give a quick brief of what Kafka is and a few details about how it works. Kafka is a distributed messaging system originally built at LinkedIn and now part of Apache Software Foundation and used by variety of companies.
The general setup is quite simple. Producers send records to the cluster which holds on to these records and hands them out to consumers:
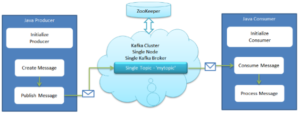
The key abstraction in Kafka is the topic. Producers publish their records to a topic, and consumers subscribe to one or more topics. A Kafka topic is just a shared write-ahead log. Producers append records to these logs and consumers subscribe to changes. Each record is a key/value pair.
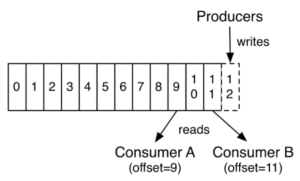
Here is a simple example of a single producer and consumer reading and writing from a two-partition topic.
Kafka Benchmarking
Scenario 1:
All of these benchmarks were run on AWS EC2 instances with the following specifications:
- Kafka cluster is running on three Machines; the spec of each Machine is Instance Type:-c3.4xlarge, 16 VCPUs, 30 GB RAM, Disk :- 2 * 160 GB (SSD’s) ,RAID:- 0 (Stripping) and XFS Filesystem
- Zookeeper running on three mahcines; the spec of each machine is of t2.micro
These benchmarks were run for the following cases:
- Single producer (single thread) and single consumer producing asynchronousyly on a topic with replication factor of 3 and 1 partitions.
- 9 producer (3 producer with three thread so total 9 (3*3) ) and 3 consumer producing asynchronously on a topic with replication factor of 3x and 1 partitions.
In this context, a producer running in async mode would mean that the number of acknowledgements the producer requires the leader to have received from its followers before considering a request complete is 0.
You may be also interested in: Working with Kafka Consumers
Case 1: Single producer (single thread) and Single Consumer producing asynchronously on a topic with replication factor of 3 and 1 partitions.
We have performed the test for various records(2 ,5,10 and 15 lakh) with different record size (10KB,5KB,2KB) by varying throughput (1000 ,5000 and 10000 )
Command:
Producer test performance command :
./bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance –topic <topic-name> –num-records 1000000 –record-size <record-size> –producer-props bootstrap.servers=<broker-list> –throughput <value>
Consumer test performance command:
bin/kafka-consumer-perf-test.sh –zookeeper <zk-list> –threads 1 –topic <topic-name> –messages 1000000
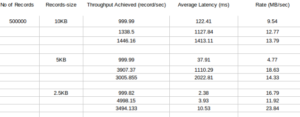
Result:
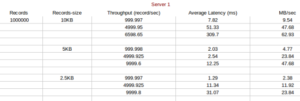
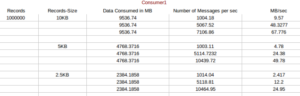
Conclusion:
1) With decrease in record size for a message the average latency decreases
2) More Throughput more Latency
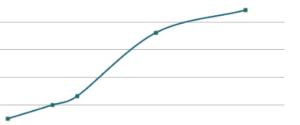
Latency
3) Throughout and Record -Size are inversely proportional.With more Record-size we have less throughput.
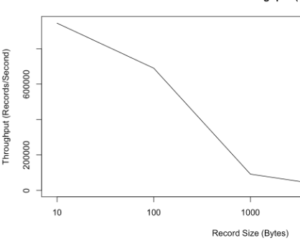
Case 2: 9 producer (3 producer with three thread so total 9 (3*3) ) and 3 Consumer producing asynchronously on a topic with replication factor of 3x and 1 partitions.
Producer
Consumer
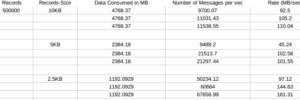
Conclusion:
By Increasing the number of Producer(compared to first case) the Latency of the producer also increases .
Scenario 2:
All of these benchmarks were run on AWS EC2 instances with the following specifications:
- Kafka cluster is running on three Machines; the spec of each Machine is c3.4xlarge, 16 VCPUs, 2 * 160 GB (SSD’s), EBS ST1 disk type, EXT4 filesystem
- Zookeeper running on three machines; the spec of each machine is of t2.micro
These benchmarks were run for the following cases:
1.Single producer (single thread) and single consumer producing asynchronously on a topic with replication factor of 3 and 1 partitions.
2. 9 producer (3 producer with three thread so total 9 (3*3) ) and 3 consumer producing asynchronously on a topic with replication factor of 3x and 1 partitions.
Case 1: Single producer (single thread) and Single Consumer producing asynchronously on a topic with replication factor of 3 and 1 partitions.
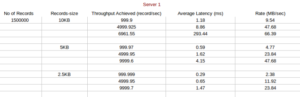
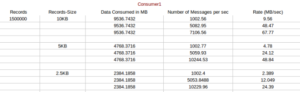
Result:
If we compare above result with Scenario 1 case 1 result ,we found that the avergae latency with EBS ST1 disk is very low.
Case 2: 9 producer (3 producer with three thread so total 9 (3*3) ) and 3 consumer producing asynchronously on a topic with replication factor of 3x and 1 partitions.
Producer
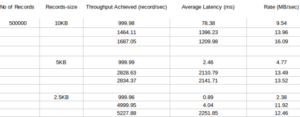
Consumer
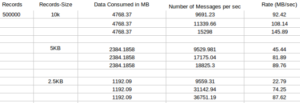
Conclusion:
With increase in producer count (compared to above Scenario 2 case 1) the Latency of the producer also increases .








