

Generative AI (GenAI) is defying economic gravity. While tech investment worldwide has decelerated amid economic headwinds, venture capital investment in GenAI startups continues to be strong. Venture capital funding for generative AI reached over $45 billion globally in 2024, as indicated in a new report by EY, nearly double the total for 2023 ($24 billion) and more than five times the value of VC spending in 2022 ($8.7 billion). The early enthusiasm for GenAI is giving way to a more practical strategy as efforts go toward practical Generative AI Implementation.
Organizations are now rushing to integrate GenAI technologies and capabilities across teams to improve efficiency and increase productivity. Early adopters of this technology are already reaping the benefits: some have improved their virtual assistant’s accuracy by 90% through integrating ChatGPT-3 with their knowledge base.
As an organization that has helped large technology companies and startups in their GenAI journeys, we understand that things aren’t always easy. Implementation presents its own challenges, from managing ethical issues to managing large data environments. In this article, we have provided the necessary steps to implement Generative AI, covered common pitfalls, and offered solutions to enable you to reap the maximum potential of the technology.
Generative AI, unpacked
What is generative AI?
The term “generative AI” refers to deep-learning models that can generate outputs such as text, images, videos, audio, code, simulations and even synthetic data based on the data they were trained on.
How it works?
Generative AI uses machine learning methods, specifically neural networks, to evaluate input data and identify underlying patterns, structures, and features. These learned patterns allow the model to create unique content that is contextually relevant.
Foundational AI models, pre-trained on extensive unlabeled dataset using self-supervised learning, form the basis of this technology. These models require significant computing resources but offer great adaptability. Though strong, their outputs tend to need fine-tuning for specific uses.
What makes Generative AI unique?
GenAI is different from traditional AI in the following ways:
Content Generation – Need an original song, a marketing campaign, or a product description? The innovative power of GenAI is revolutionizing the way businesses are creating content.
Learning and Adaptability – GenAI can learn and adapt in real time, unlike static models of AI. It is a handy resource for dynamic environments, as it gets smarter with every interaction.
Human Interaction – Natural language processing (NLP) GenAI models are capable of having real conversations. They can sense intent, tone, and even sarcasm, something that regular AI finds difficult to do.
The steps for successful Generative AI implementation
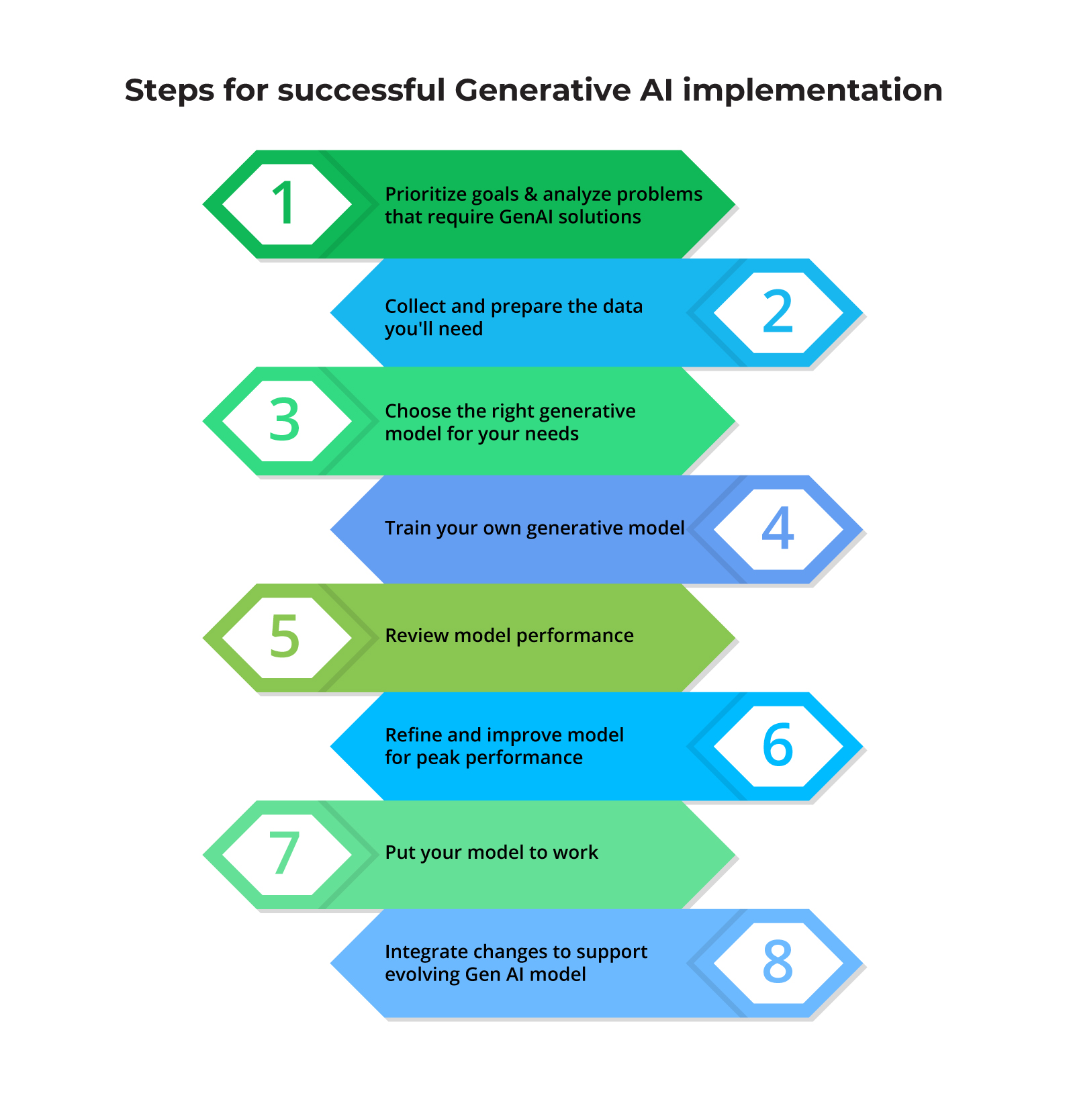
Step 1: Prioritize goals and analyze problems that require GenAI solutions
Generative AI can solve many problems, but without clarity on your core issue, you risk missing the mark and lowering your ROI. Start by clearly defining the problem you want to solve with generative AI before you dig deep into the technical aspects. This phase sets the foundation for your generative AI implementation, aligning efforts with strategic goals. It involves brainstorming ways that generative AI could solve challenges in marketing, sales, product development, service operations, or other areas.
Next, brainstorm specific use cases that fit your company’s unique business context and analyze how they map to your top priorities. For example, if you’re creating photos for e-commerce, assess the aspects like realism, diversity, and model’s guiding abilities. Similarly, for text generation, make sure the language is natural, contextually appropriate, and engaging.
When reviewing each use case, be sure to evaluate the ease of implementation, anticipated ROI, and any ethical or legal implications involved.
This step will provide you with a clear, prioritized list of use cases. Each one with concise descriptions, practicality assessments, arguments for their benefits, information on the infrastructure required, and compliance considerations. All these elements should be strategically ranked and aligned perfectly with your business goals.
Step 2: Collect and prepare the data you’ll need
Once you understand your goals, the next step is to collect and prepare the data to train the generative AI model. This data forms the foundation for model learning and directly influences its performance.
Gathering high-quality data is essential. Begin by collecting a robust dataset tailored to your specific use case, ensuring it accurately reflects the variations and characteristics you want the model to learn. This foundational step will significantly impact the model’s effectiveness.
Here are some tips for data collection:
- Explore publicly available datasets relevant to your chosen area, such as text corpuses, image collections or audio samples.
- Leverage existing data within your organization, such as customer reviews, product descriptions, or social media interactions.
- Carefully consider scraping data from the web, ensuring ethical and legal compliance while focusing on relevant and trustworthy sources.
Let me elaborate this further with a real-life instance where we helped one of our clients in the email marketing domain create a high-quality dataset. Our AI experts carefully supercharged their existing customer data, such as reviews and social media interactions, with AI-driven insights. This enabled them to generate highly targeted email content and improve their open rates.
The model’s efficacy depends on data quality, which is why the dataset must be free of errors, inconsistencies, and irrelevant information. For example, NHTSA research found that women are 17% more likely than men to die in car crashes, despite being safer drivers. This disparity arose because crash tests often exclude female dummies or place them only in the passenger seat. Having a diverse data set can help to avoid bias and enhance the model’s ability to generalize effectively.
In many cases, data needs proper labelling too. This involves providing context to the data so that your model can understand and learn from it effectively. Techniques such as crowdsourcing, active learning, or semi-supervised learning can streamline the labeling process while improving accuracy.
Data can be messy. It requires cleaning to remove any noise or irrelevant information. In some cases, you can create more data by augmenting your dataset through different methods. For images, this could include rotating, scaling, and flipping. In the case of text, it could involve replacing synonyms or paraphrasing.
Once the data is ready, store it in an easily accessible format in cloud storage, data warehouse, or distributed file system for the prototyping and development phases.
Step 3: Choose the right generative model for your needs
Choosing the wrong model can result in inefficient use of resources, suboptimal outputs, and longer training durations, limiting your ability to fully utilize the potential of generative AI. For example, if you need to build a model to detect emotions from images, using a model primarily tuned for text analysis can result in inaccurate or irrelevant outputs, as it lacks the necessary optimization for visual data.
Models aligned with your user story can increase the effectiveness of your product. There are different types of Generative AI models, each with its strengths.
Generative Adversarial Networks (GANs): Ideal for generating realistic images but require careful training and tuning to avoid mode collapse and ensure stability. GANs such as StyleGAN and Stable Diffusion XL Base 1.0 are perfect for generating diverse and high-fidelity images
Variational autoencoders (VAE): They provide a probabilistic interpretation of the data, allowing control of the generation process. It is valuable in generating additional data points to enrich your existing data set.
Autoregressive models: Great for text and sequence generation but can be computationally expensive for long sequences. Models such as GPT-3 and Jurassic-1 Jumbo are pushing the boundaries of text generation, delivering impressive fluidity and creativity.
After selecting the right model, the next step is to design custom architecture. For GAN, define the structures of the generator (creates new data) and the discriminator (distinguishes real data from generated data). In case of VAEs, design the encoder (compresses the input data into the latent space) and the decoder (reconstructs the original data from the latent representation). If you want to work with an autoregressive model, select the specific model architecture (such as GPT-3) that aligns with your needs and tune the model hyperparameters (learning rate, batch size, number of layers) to optimize its performance.
Step 4: Train your own generative model
If you neglect or poorly execute the training process, your models will produce inaccurate, low-quality results that fail to generalize effectively to new data. This can jeopardize your project goals and waste valuable resources. Effective training ensures that your model learns from the data, capture patterns, and generates results that match your expectations. Simply put, without sufficient training, even the best-designed generative model will not perform to its full potential.
Training a neural network starts with initializing parameters like layers, activation functions, and weights to set the stage for effective learning. The next step involves defining a loss function to gauge the accuracy of the model’s output against the target, specific to the generative model type.
Adversarial loss for GAN.
- Reconstruction losses for VAE.
- Cross entropy loss for autoregressive models.
Training involves feeding data into the model, calculating the loss, and adjusting parameters using optimization and backpropagation. Opting for an algorithm like Stochastic Gradient Descent (SGD) or Adam fine-tunes the model’s weights to minimize loss effectively.
Step 5: Review model performance
After training, evaluate your model using evaluation metrics for quality and performance of the generative model. The step is crucial to ensure these models are not just effective but also ethical, reliable, and aligned with the specific needs of their applications.
For the generated images – use the initial score (IS) and Fréchet initial distance (FID). To measure how well the model predicts the sample- use Perplexity. Less perplexity means the model is more confident in its predictions.
To ensure your model generalizes effectively and avoids overfitting, it’s essential to split your data into distinct training and validation sets. Begin by training the model on the training set, which allows it to learn patterns and relationships within the data. Then, evaluate its performance using the validation set, which acts as a proxy for unseen data. This approach helps you assess how well the model can apply its learned knowledge to new, unseen examples, ensuring that it performs robustly in real-world scenarios and not just on the data it was trained on.
Step 6: Refine and improve model for peak performance
Once the initial training is done, it is crucial to refine and improve the model’s performance. This involves:
Hyperparameter tuning:
You might have to adjust knobs and dials (hyperparameters) to improve the model’s learning process. Tune hyperparameters such as learning rate, batch size, and number of layers to optimize model performance. Use techniques such as grid search or random search to explore different combinations of hyperparameters and identify the best configurations
Regularization techniques:
Apply regularization techniques such as dropout, weight decay, and batch normalization to avoid overfitting and improve generalization. These techniques help prevent the model from overfitting to the training data. This ensures it can generalize well to new data it hasn’t seen before.
Iterative improvement:
This step requires continuous monitoring and refining of the model based on evaluation metrics and validation performance. You must repeat the training and evaluation steps until it meets your performance goals. This will allow you to tune the model and fix any issues that can hinder its performance.
Step 7: Put your model to work
If the performance is satisfactory, deploy the model for real-world use. Integrate it into your application or service. This might involve setting up APIs or integrating the model into a software pipeline. Ensure seamless integration with your existing systems and infrastructure. You can do this by setting up APIs or integrating the model into software pipeline.
As your needs grow, scaling the model may become necessary. It’s crucial to ensure that the deployment infrastructure is capable of handling the evolving computational and scalability demands, whether for real-time processing or batch generation. This preparation guarantees that the model can perform efficiently and reliably as its workload increases. Cloud-based solutions and distributed computing frameworks can help you with scaling the model effectively.
But monitoring the model’s performance in real-world use is also important. Set up logging and alert systems to track model results and detect any anomalies. This allows you to proactively identify and address issues in production.
Step 8: Integrate changes to support evolving Gen AI model
Long-term effectiveness of the model depends on constant incorporation of updates. This requires planning with steps like:
Continuous learning
The model should have continuous learning mechanisms to be updated with new data and improve performance over time. This you can set through online learning techniques or regular updates with new data sets. Continuous learning helps the model adapt to changing data distributions and remain effective.
Feedback loop
A feedback loop from users or the application helps refine the model through mechanisms like user input, error analysis, and result tracking. It also provides valuable information about the model’s performance in real-world scenarios and helps identify areas for improvement.
Periodic retraining
Periodically retrain the model with updated data to ensure it remains accurate and relevant. The frequency of retraining will depend on the rate of data change and the desired level of accuracy. Retraining on new data helps the model stay up to date and adapt to evolving trends or patterns in the data.
Note: RAG (Retrieval-Augmented Generation) can be a crucial tool for Gen AI models here. The model can continuously retrieve the latest data from external sources by incorporating retrieval-based processes, allowing it to provide updated information in response to changing requests. RAG ensures that the LLM models do not solely depend on static training data but also incorporates new, real-time data for more precise and context-sensitive responses.
To further understand how implementing a RAG pipeline can improve the accuracy of AI system/chatbot, by retrieving up-to-date information from relevant documents, our application development lead, Madhumitha Madhuramani, explains it in detail. You can read it here – How to Implement RAG Pipeline Using Spring AI

Challenges of implementing generative AI
Anticipating and understanding potential bottlenecks during the implementation of a generative AI solution is crucial for crafting an effective deployment strategy. If you can identify these challenges in advance, you can proactively address issues related to computational load, data throughput, latency, and model efficiency.
Data security and privacy
Generative AI implementation raises significant concerns about data security and privacy. Training these models requires large data sets, which increases the danger of disclosing sensitive information. Improper handling of personal data can lead to major breaches and non-compliance with regulations such as GDPR, DORA, and HIPAA. Furthermore, models trained on sensitive data may inadvertently provide results that disclose private information, raising ethical challenges and putting anonymity at risk.
To manage these risks, companies can take two key approaches. First, they can leverage open-source Large Language Models (LLMs), offering full control over data handling and model deployment. This approach, however, demands substantial investment in time and resources for customization and validation. Alternatively, companies can opt for trusted cloud services like Microsoft Azure, which prioritize data privacy and offer robust security measures, providing a more streamlined solution. This approach allows for faster implementation while maintaining privacy regulations and protecting sensitive information.
Ethical and bias considerations
Generative AI models are inherently subject to hidden biases in their training data, which can lead to unethical outcomes and propagate negative preconceptions. In July 2023, Buzzfeed sparked controversy by using Midjourney to create Barbie designs for 193 countries. The German Barbie was depicted in a Nazi uniform, and the Thai Barbie was portrayed as blonde, highlighting deep-rooted racial biases in the AI-generated content.
To reduce bias, datasets need to be properly assessed for fairness and representation. Bias detection algorithm and diverse data collection practices can make models more balanced with inclusive datasets. Increasing transparency in how models make decisions and create outputs can also increase user trust and support responsible generative AI implementation.
Computational cost and resources
Efficient generative AI implementation requires large computational resources, which can be a significant challenge for businesses. Generative AI models, particularly large language models (LLMs), demand enormous processing power and memory. As these models become more complex, the need for high-performance hardware such as GPUs and TPUs increases, resulting in significant operational expenses.
Scaling AI operations can exponentially increase these expenses, particularly when continuous retraining or deployment across multiple environments is required. It makes balancing cost-effectiveness with model performance more critical for businesses with tight budgets.
Avoiding these requires a careful evaluation of the computing needs and costs. Companies should explore options accordingly. Third-party services, such as OpenAI, offer quick installation and cheaper upfront expenses, making them attractive for smaller applications or those in the early stages of AI adoption. But there is a catch. As AI usage increases, these services can become more expensive, especially when working with complicated or large-scale models.
In contrast, open-source LLMs such as LLaMA or Meta’s OPT can become more cost-effective over time, offering greater flexibility and lower operational costs, by allowing for customization and control of deployment. Organizations can strike a balance in their generative AI projects by anticipating future demands and potential scalability.
Intergration with existing systems
Integrating generative AI models into existing systems can be a complex and resource-intensive task. This process often involves significant challenges, such as frequent compatibility issues and potential outages that can reduce overall efficiency and disrupt established workflows. In addition, the integration process can require specific expertise, which can be a barrier for teams that lack the necessary skillset.
To ensure smoother integration, start by assessing your existing IT capabilities and infrastructure for probable compatibility issues. Build powerful APIs to facilitate seamless communication between AI models and existing applications. Most importantly, invest in a skilled team with expertise in both AI and system integration to oversee the process. If your internal resources are limited, consider outsourcing specific tasks or collaborating with AI experts.
Data quality and quantity
The performance of generative models heavily depends on the quality and quantity of training data. Insufficient data can affect your model’s ability to generalize, while too much data can lead to computational burden and longer training times. Moreover, noisy or unrepresentative data can directly impact your model’s accuracy. A mismatch between training data and real-world situations can further compromise performance.
Adopt strategic approaches to address these issues. For insufficient data, semi-supervised learning methods can be useful. These methods use both labeled and unlabeled data, allowing models to learn from smaller data sets while simultaneously adding new information. To handle large amounts of data, automated data sampling methods can be used to generate representative subsets that retain important information while reducing processing demands.
For better data quality, implement a strategy comprising rigorous data cleaning and validation procedures to ensure the model is learning from trusted data source. Remember that a model is only as good as the data it is trained on, therefore continuous monitoring and improvement is required for optimal performance.
Two emerging technologies (confidential computing and platform engineering) also offer promising solutions to the challenges associated with generative AI implementation. Let’s explore them as well:
Platform Engineering
Platform engineering focuses on creating frameworks that support the entire AI model lifecycle, from development to monitoring. By providing standardized tools and processes, platform engineers enable developers and data scientists to concentrate on GenAI without worrying about the underlying infrastructure.
Confidential computing
Confidential computing enables encryption for data at rest and in transit, ensuring that sensitive workloads can be securely managed by cloud assets. This protection extends even while data is being processed.
This technology is particularly useful for training AI models on private datasets as it allows controlled access to data while protecting privacy and security. It also improves model transparency by producing non-repudiable data and records of model provenance.
Different Generative AI models and their use cases
| Generative AI Model | Benefits | Use Cases |
| GPT-4 (Large Language Model) Description Advanced language model with exceptional context understanding, nuanced language generation, and multi-modal capabilities. | Creates human-quality text formats. | Chatbots with rich conversational abilities. |
| Handles complex prompts and instructions. | Content creation assistance (writing, code generation) | |
| Integrates different media formats (text, code, images) | Multilingual content translation | |
| Mistral (Mixture of Experts) Description Utilizes a Mixture of Experts (MoE) architecture. | Enhances efficiency and effectiveness in NLP tasks. | Advanced natural language processing applications. |
| Provides personalized recommendations based on user data. | Personalized content recommendations (e.g., streaming services, e-commerce). | |
| Offers innovative solutions for complex challenges. | Complex problem-solving in various domains (finance, healthcare, technology). | |
| Gemini (Multi-Modal Content Creation) Description Specializes in multi-modal content creation. | Generates text formats that are both informative and engaging. | Social media content creation (text, images, videos). |
| Integrates text with visuals for a richer user experience. | Marketing materials with a blend of text and visuals. | |
| Creates unique and original content ideas. | Interactive storytelling experiences. | |
| CTRL (Context-Aware Text Generation) Description A large-scale transformer model. | Ensures text aligns with a specific tone, style, or purpose. | News article generation with targeted styles (e.g., breaking news, opinion pieces). |
| Maintains consistency and coherence in generated content. | Marketing copywriting with specific keywords and brand voice. | |
| Offers flexibility in controlling the creative direction of text. | Personalized creative text formats (e.g., poems, scripts). | |
| StyleGAN (Generative Adversarial Network) Description A powerful GAN variant for image synthesis with exceptional control over details. | Generates high-fidelity, realistic images. | Generating product mockups with diverse styles and variations. |
| Allows for fine-tuning image styles and features. | Creating realistic portraits with user-defined characteristics. | |
| Creates images at various levels of detail and resolution. | Fashion design applications (e.g., prototyping clothing styles). | |
| Pix2Pix (Image-to-Image Translation) Description A GAN-based framework for translating images from one format to another. | Enables seamless image conversion tasks. | Transforming satellite images into detailed maps. |
| Offers high-quality image translation results. | Colorizing black and white photos for a more modern look. | |
| Applicable to a wide range of image types. | Artistic image style transfer (e.g., applying a specific painting style). | |
| DeepDream Description An AI-based image generator. | Offers unique artistic expression through AI. | Artistic exploration and experimentation. |
| Provides insights into neural network activity for research purposes. | Neuroscience research on visual perception and processing. | |
| Generates visually captivating and thought-provoking images. | Creating dream-like visuals for games or multimedia projects. | |
| DALL-E (Generative Pre-Trained Transformer) Description Generates photorealistic images based on textual descriptions. | Creates highly realistic images from user-provided text prompts. | Generating product concepts with realistic visuals. |
| Offers a powerful tool for visual communication and ideation. | Creating illustrations for books, games, or marketing materials. | |
| Enables exploration of diverse image concepts through text. | Visualizing scientific data or complex ideas through images. | |
| Midjourney (Diffusion-Based Generative Model) Description Creates artistic images with a focus on various artistic styles. | Offers a wide range of artistic styles for image generation. | Generating concept art for video games or animation projects. |
| Enables exploration of artistic inspirations and techniques. | Creating artistic tributes to famous artists’ styles. | |
| Creates unique and visually compelling artwork. | Generating artistic visuals for music albums or creative projects. | |
| GitHub Copilot Description An AI-powered code completion tool. | Faster code writing and reduced boilerplate code. | Completing common tasks, generating repetitive code, and suggesting efficient solutions. |
| Minimizes common coding mistakes. | Preventing syntax errors and suggesting safer coding practices. | |
| Provides insights into new patterns and solutions. | Exploring different approaches, learning new libraries and frameworks, and understanding complex code concepts. |
Conclusion
Generative AI presents significant opportunities for companies in all sectors. Businesses can reap significant benefits by using technology to develop entirely new content, automate activities, and personalize experiences. This comprehensive guide has provided you with the basic knowledge to navigate the exciting world of generative AI implementation. We explore the different types of models, delve into the practical steps involved, and provide insights into best practices for successful implementation.
However, implementing generative AI requires not only technical competence, but also a deep understanding of your company’s particular goals and needs. At Talentica, we understand the intricacies of both technology and business needs.
We’ve built 200+ AI-driven products for startups and tech giants since 2003. Our top 2% engineers are trusted for long-term success, helping clients scale from Seed to unicorn. The GenAI team we have is a perfect blend of data scientists and developers and they can save you the effort of finding top talent.
Ready to see how GenAI can accelerate growth and boost efficiency in your business? Contact us today! Or email us at: info@talentica.com
Generative AI Implementation – FAQs
How can I select the right generative AI model for my business?
The first step in selecting the best generative AI model for your business is to determine your needs, whether it’s customer service, content production, or something else entirely. Make sure the models you’re considering fit your goals and current infrastructure. Verify they meet security requirements, especially if you handle sensitive data.
Naturally, consider your budget and available resources before making any decisions. By conducting in-depth research or consulting with a specialist, you’ll be able to make an informed decision.
What impact does data quality have on generative AI implementation?
Data quality is essential to the success of generative AI implementation. High-quality, diversified, and unbiased data ensures accurate and reliable results, but low-quality or inadequate data can produce incorrect results. It is essential to invest in quality data collection and preparation before using AI because poor quality data can produce biased or erroneous results.
What are some important considerations to keep in mind during generative AI implementation?
There are certain key things to consider when implementing generative AI. First, ensure that the AI is scalable with your business and that it is aligned with your objectives. You also need to think about data security and privacy, particularly if you’re dealing with sensitive information.
To make sure the model delivers high-quality output, testing and tuning are essential. Lastly, ensure that it is within your budget, taking into account costs, such as implementation and maintenance.
What are the most important steps in the implementation of generative AI?
Key steps involve finding the appropriate use cases that suit your business needs, choosing the appropriate AI models, training the models using relevant data, and integrating these models into your current workflows seamlessly in order to achieve maximum efficiency.
How long does generative AI implementation take?
The timeline depends on the project’s complexity, the size of the generative ai implementation, and data availability. Small projects can take weeks, while big implementations may take months.









