

In this blog we’ll explore the internals of how Git works. Having some behind-the-scenes working knowledge of Git will help you understand why Git is so much faster than traditional version control systems. Git also helps you recover data from unexpected crash/ delete scenarios.
For a developer, it is quite useful to understand the design principles of Git and see how it manages both speed of access (traversing to previous commits) and small disk space for repository.
In this blog, we will cover the following topics:
- Initializing a new repository
- Working directory and local repository
- Git objects
- Blob
- Tree
- Commit
- Tag
- Packs
I’m using Ubuntu 16.04 LTS, Zsh terminal and Git v2.7.4 for this blog, but you can use any operating system and terminal to follow along.
Initializing a new repository
- Initialize a new Git repository with ‘git init’ command.
- Create a couple of files by running the following commands.
$ echo “First file”>>first.txt
$ echo “Second file”>>second.txt
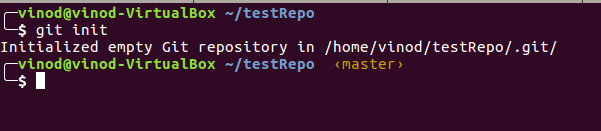
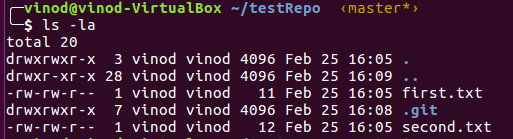
- Run ls –la to display all the contents of the folder.
It should show .git directory and the two files we created.
Working directory and local repository
Working directory comprises of the files and folder we want to manage with Git Version Control System (VCS). In this case ~/testRepo folder constitutes our working directory except for ‘.git’ folder. .git folder forms the local repository. ‘.git’ folders contain everything that Git stores to manage our data.
Git objects
Git doesn’t store diff of the contents of the file. It stores snapshots of each file, that is each version of the file is stored exactly as it is at the point it is staged and committed. This is done for faster access, one of the core principles for development of Git.
The latest version of the file is always stored as is in Git as it is most likely the one to be used. Also, storing it makes it much faster for retrieve operations.
As further versions of the file are added, Git automatically creates pack files. We’ll discuss more on pack files later.
There are 4 types of git objects.
- Blob
- Tree
- Commit
- Tag
Let’s understand these with an example. First let’s check the contents of .git folder.
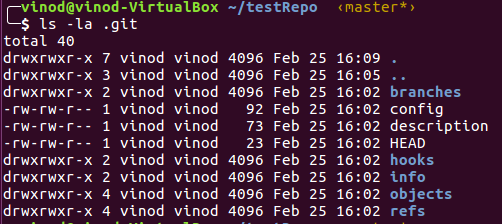
There are 5 directories and 3 files. Let’s start with objects.
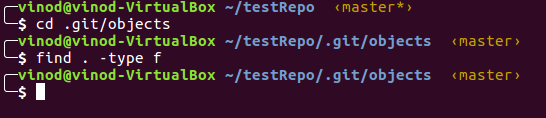
Find command returned no results, i.e. there are currently no files in objects folder. Let’s stage our two files and then check.
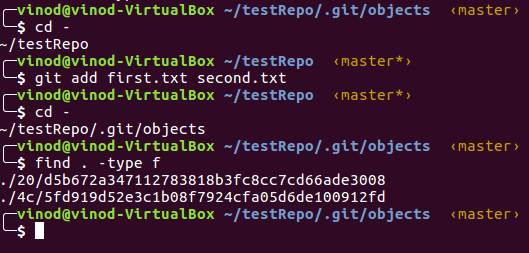
We can see that there are two files. To explore these objects, we would need to use the command ’git cat-file’
From the main pages of the Git cat-file, “Provides content or type and size information for repository objects”
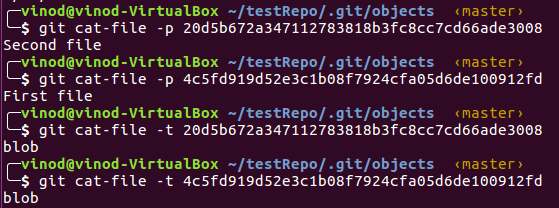
-p argument pretty-prints the object contents and –t returns the type.
The objectId(SHA-1 Id) is subpath of the file from .git/objects folder without the slashes.
For example, object Id of .git/objects/20/d5b672a347112783818b3fc8cc7cd66ade3008 is 20d5b672a347112783818b3fc8cc7cd66ade3008.
The type that was returned for both the objects is blob.
So blobs are objects used for storing content of the file. Blobs just store the content, no other information like file name.
Let’s commit our code now with ‘git commit’ command.
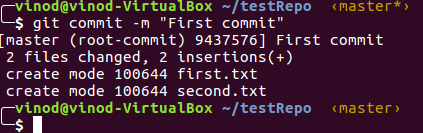
Next, run ‘git log’ to retrieve the commit ID.
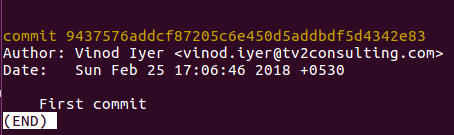
Copy the commit ID and then run cat-file commands on it.
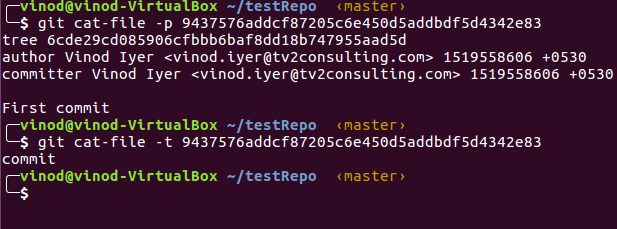
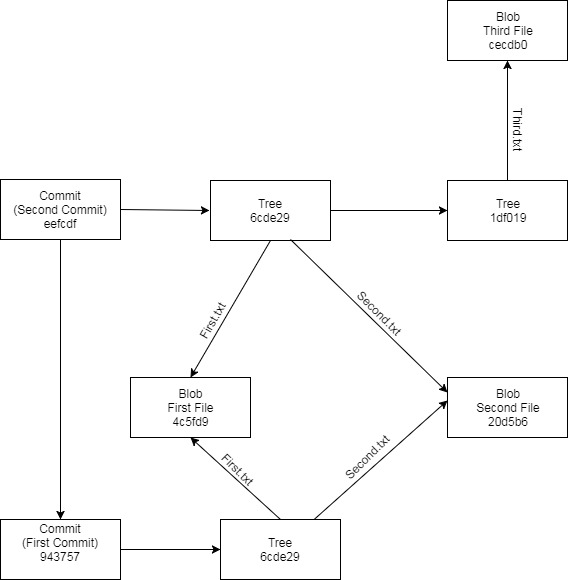
The object type that is returned is ‘commit’. It contains reference to a tree object, author name, committer name and the commit message.
Now let’s check the tree object.


The tree object contains reference to the blob files we saw earlier, and also the reference to file names. We can summarize our Git repository state at this point with the following object diagram:
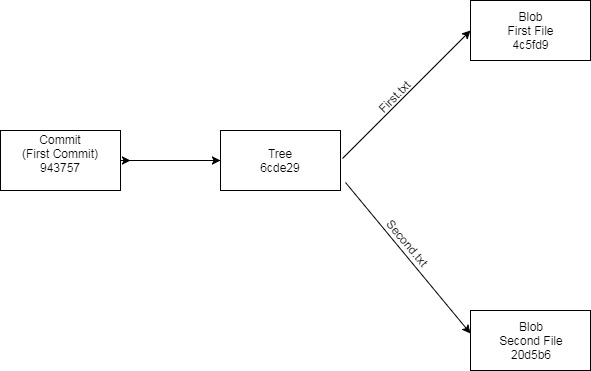
Let’s add a folder to our repository.
Run the following commands. We’ll use ‘git add’ to add folder from working directory to the local repository.
$ mkdir fol1
$ echo “Third File”>> fol1/third.txt
$ git add fol1
$ git commit -m “Second commit”
Inspect the second commit object.
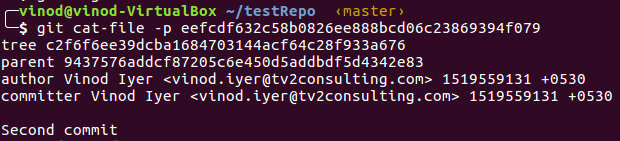
Notice that the tree reference has changed. Also, there is a parent object property. So commit object also stores the parent commit’s id. Let’s inspect the tree.
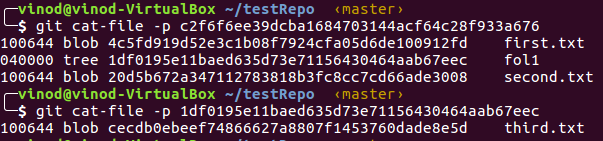
The folder we just added, fol1, is stored as a tree and it contains reference to a blob referencing third.txt file. So tree objects reference blobs or other sub tree objects.
Now let’s discuss tags. Tags are used to provide an alias to a commit SHA ID for future reference/use. There are two types of tags: lightweight tags and annotated tags.
- Lightweight tags contain only the SHA-ID information.

The command ‘git tag light’ creates a file under .git/refs/tags/light which contains the commit Id on which the tag was created. No separate tag object is created. This is mostly used for development purposes, to easily remember and traverse back to a commit.
- Annotated tags are usually used for release. They contain extra information like message and the tagger name along with the commit ID. Annotated tags can be created with ‘ git tag –a –m “<message>” ‘ command.
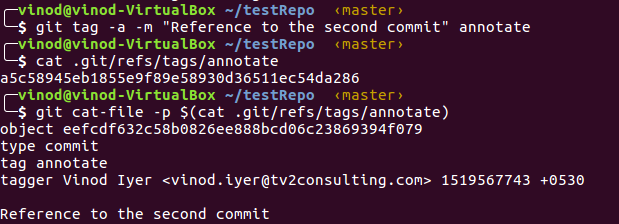
A separate tag object is created for annotated tag. You can list the tags created with ‘git tag’ command
Packs
- Although Git stores the contents of the latest versions of object intact, the older versions are stored as deltas in pack files. Let’s understand with an example. We would need a slightly larger file to see the difference in size of the delta file and original file. Download GNU license web page.
- Run the following command to download the license HTML file.
$ curl -L -O -C – https://www.gnu.org/licenses/gpl-3.0.en.html
You should now have gpl-3.0.en.H file in your working directory.
- Add and commit the file.
$ git add gpl-3.0.en.html
$ git commit -m “Added gpl file”
Inspect the commit and get the blob info of the added file.
git cat-file -p 53550a1c9325753eb44b1428a280bfb2cd5b90ef
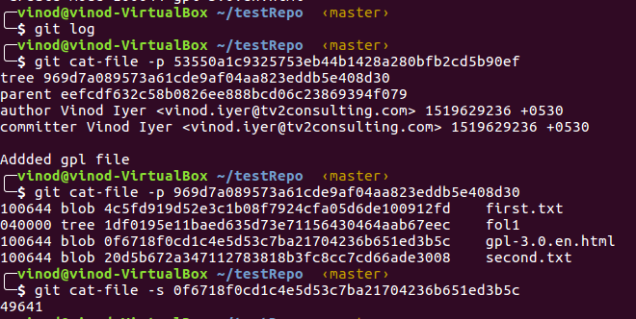
The last command returns the size of the blob. That is the blob containing content of gpl-3.0.en.html is 49641 bytes.
4. Edit the file and commit it again.
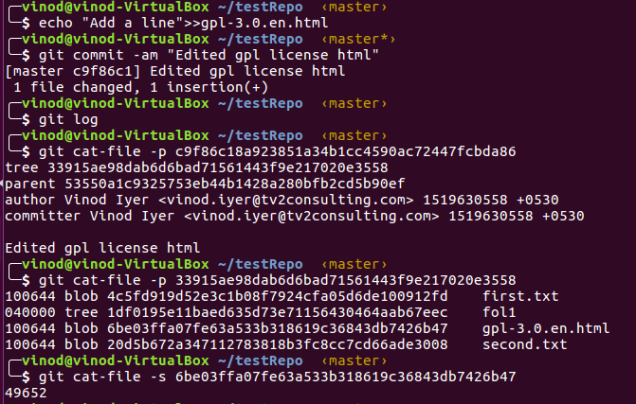
A new blob is created with a slightly larger size. Now let’s check the original blob.

The original blog still exists. Thus for each change, a snapshot of the file is stored with its contents intact.
5. Let’s pack the files, with ‘git gc’ command.
As you can see, all of our existing blob and commit objects are gone and are now replaced with pack files.
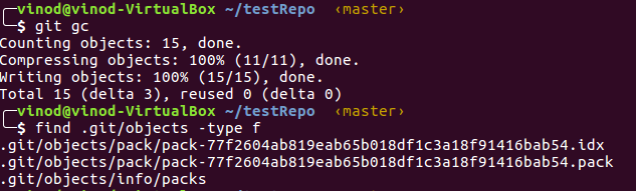
6. We can run ‘git verify-pack’ command to inspect the pack file.
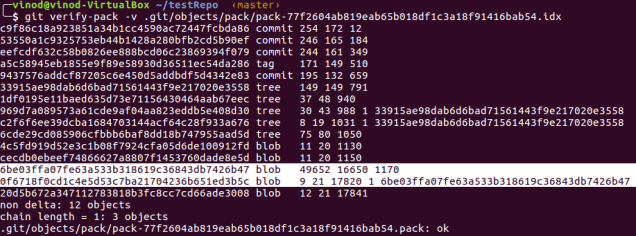
Now let’s check the highlighted entries.
The blob with commit ‘6be03f’ is the second version of gpl-3.0.en.HTML and the one with commit ‘0f6718’ is the first version.
The third column in output represents the blob size. As you can see, the first blob is now reduced to 9 bytes and references the second blob which maintains its size of 49652. Thus the first blob is stored as a delta of second blob although the first one is older. This is because the newer version is most likely to be the one to be used. Git automatically calls pack when pushing to remote repository.
Conclusion
In this blog we explored how Git stores the files internally and looked at the various types of Git objects, i.e, blob, tree and commit and how they are linked to each other. Then we also looked at packs, which explained how Git compresses older versions of a file and saves storage space.








