

In the previous blog in this series (Part 1), I discussed the overall concepts of deduplication, available tools, and the challenges involved in solving problems where we only have short text as names.
In this blog, I will delve into how we can utilize custom machine-learning methods to group similar company names without considering other contextual information or cases where the context is inconsistent.
The overall algorithmic pipeline will resemble other open-source solutions in the literature, incorporating processing steps such as indexing, pairing, feature extraction, pair binary classification, and grouping.
- Analysis and Name Cleaning
- Pairing
- Extracting features
- Model Training & Inferencing
- Grouping
- Evaluation
- Productionalization
By constructing a modular pipeline, we can employ more suitable and highly customizable steps, rather than relying solely on the configurations provided by the listed frameworks. Custom code in each step can enhance the detection and performance of each component independently.
Preprocessing
While text processing might require different steps based on data variations, some of the steps that can be followed are listed below.
To detect and clean industry/sector specific keywords:
- Split each text and take the frequency of each word across all-names
- Inspect words with a higher frequency, and filter as required
To filter and keep only relevant name portions:
- Parse using probablepeople or python-nameparser
For cleaning location entities:
- Use iso3166 package for country name removal
- Geocoder using usaddress package to remove address variations
For correcting spelling mistakes:
- Use TextBlob package
In this section, we will dedicate the majority of our time. Enhanced cleaning processes will assist us in improving the similarity scores of related records and eliminating noise from irrelevant sections. It’s important to note that under-cleaning is preferable to over-cleaning, as over-cleaning can lead to the merging of irrelevant texts into the same group due to a lack of differentiation.
Pairing
This step is essential for generating candidate record pairs for feature extraction. It significantly reduces computational complexity from N^2 to a more manageable linear N x M (with M being the window size).
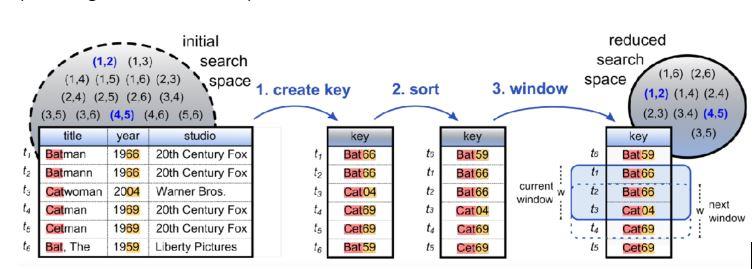
There are various other options available like Q-Gram-based indexing, Suffix-array-based index, Sorted Neighbourhood, Canopy Clustering, Mapping Based index. For Sorted Neighbourhood blocking, we can use recordlinkage, or Magellan package (pyentity-matching).
While these techniques can significantly reduce the search space and computational complexity, we may observe the exclusion of some important pairs in both training and test data, leading to a loss of accuracy. The quality of pairs can also be a challenge if the key is not constructed correctly with the appropriate cleaning and processing. I recommend conducting a key-pairs loss analysis and comparing performance at various thresholds to minimize this loss.
Feature Extraction
We can use the textdistance package containing 30+ algorithms across Edit-based, Sequence-based, and Phonetic similarity functions and simple algorithms for prefix/suffix or exact similarity.
Other packages for similarity functions can be explored from python-string-similarity.
Some selected features may not improve performance but can consume significant computational resources. These can be eliminated post-training using feature-importance plots or sensitivity analysis.
While structural similarity can be quite helpful, especially with longer texts, in the case of short text, names may be represented as synonyms, requiring an understanding of their meanings. Semantic similarity using language models (E.g. Transformer) can help us in these cases with better deep feature representation.
Model Training
We can experiment with various ML algorithms, from traditional to deep learning ones. But, given that we have already extracted the features, starting with a classical ensemble model like RandomForest or XGBoost is a good option.
We must carefully split the dataset to capture diverse variations across domains in the training data while ensuring that the test data remains separate from the training set.
We can evaluate the model’s performance using precision metrics and fine-tune it to reduce false positives.
Grouping
Why do we need grouping? The pairing steps before feature extraction have transformed the data domain from the original N to NxL (where L represents the window size). However, we require our group results on the original per-record basis. To achieve this, we need to create groups based on ML predictions that consider the probability of similarity between pairs.
To remap the pairs from the N^2 or NxL complexity back to the original individual record domain, we can employ graph-partitioning methods or clustering techniques for community detection. Additionally, we can utilize algorithms available in packages like dedupe (such as Hierarchical Clustering) or recordlinkage (including K-Means Clustering).
Evaluation
In this step, we evaluate the overall performance of the pipeline in grouping similar records and report metrics as % of cases where the predicted group name matches the actual one. Additionally, we can report at the group level, whether the group content matches exactly or partially, even if the group head names don’t match.
To determine the confidence probability of each group, consider the strength of the weakest link within each group. This approach will allow us to calibrate the threshold according to the required precision.
Productionalization
Creating the first cut POC is easy but deduplication usually doesn’t get solved in one go. Businesses have varied thresholds for the acceptable accuracy of the algorithms in production. Achieving accuracy in specific contexts necessitates robust testing to ensure generalization across various domains.
To analyze which of these groups require more attention, we can compare the number of names in the expected group to the ML-predicted groups and check where names are common to both groups. We can further segregate matches based on cases where the group content is the same and cases where only the name matches but the group content is not the same. Below are some cases we can examine.
- Check where group content matches but the expected and predicted names don’t match
- Check which predicted groups have significantly different sizes than expected
- Check which group sizes are similar but constituent names are different
- Check which original groups are split by ML
- Check which groups are merged by ML
Splits and merge analysis will enable us to detect if we are overcleaning or if more cleaning is required.
During POCs, we can start by annotating a subset for initial ML and evaluation. However, when we delve into the entire category, we may discover cases that were incorrectly annotated due to the underlying assumptions of certain fields not always holding true. Consequently, we may need to review annotations multiple times based on learned consistency patterns.
In production, while it’s possible to predict the group of a single new record by sampling a few records from existing groups and creating pairs for ML features, it is best achieved through batch predictions for all records and then creating a dictionary from the outputs. The dictionary can be updated periodically based on the frequency of new record arrivals. Usually, a weekly batch job or on-demand updating of the dictionary is required for support.
Detecting Grouping Issues
To check why a given name is part of a predicted group, we can first list which are names predicted to be similar for each record in the test data, by querying the pair prediction file output of ML inference, where the record is present in either index of a tuple.
To find which groups were split by ML, we can group on predicted groups, and check which groups contain more than 1 true group. Similarly, to identify which groups were merged by ML, create group by each true group and check for ML groups containing more than one true group. Initially, we should focus on cases where the expected group size is one to detect merging issue patterns.
Sometimes ML prediction can be correct but there can be levelling mistakes. These issues can be detected by examining predicted groups with high probabilities and manually validating the similarity of the manual group with nearby similar manual group names sorted alphabetically. Sorting is one of the best tools to detect issues, and can also be applied to predicted group-names to detect inconsistent manual groups.
Best Practices/ Helpful Tips:
Complexity of the solution will depend on the data complexity and variability. But a structured approach can expedite the path to production.
- Data cleaning is the most significant but proper analysis of variations is paramount
- Prioritize tasks based on the largest gain in accuracy with minimal coding efforts
- Keep track of experiments with git commit of changes in each experiment with descriptions
- Keep code clean and review well before merging with the git main branch
- To find possible annotation issues, use predictions of multiple algorithms, and check if the majority vote matches the labels.
Conclusion
Variations in data across industries always trigger new challenges. But the suggested method can assist you in gaining fresh and practical insights into the potential for duplications based solely on textual data fields, particularly for names of organizations, individuals, or products. ML-based solutions can learn intricate patterns and excel when tuned meticulously through structured analysis.









