

Evolving digital technologies are constantly opening up different data sources across companies and departments. Linking these datasets is challenging due to missing common keys, which then results in duplicate entries in the databases.
Businesses often scan through vast public records with millions of entries with possible linking via misspelled first name, last name, address, date of birth, etc. Inaccurate entries can create duplicate data. Manual efforts using spreadsheets to sort these out can lead to errors.
Duplicate data is one of the top obstacles to the business community. It reduces the accuracy of business insights and impacts the operating cost of a product and service offerings. On average, around 97% of organizations face this problem. They experience productivity issues, which then trigger more spending per client and repeated follow-ups. Because of these, the customer experience takes a hit, and churn goes up. Problems such as these can lead to a loss in revenue of around $3 trillion per year.
Duplicates can also occur due to variations in content resulting from manual entries, which can lead to spelling mistakes, truncated text, and variations in punctuation, or when sourcing data from different sources. Managing such duplicate content is a significant task, especially for data-intensive businesses. It prevents businesses from generating useful insights and results in a significant loss of man-hours spent on data cleaning. While many businesses choose to outsource the data cleaning process, this step comes with the risk of inaccuracies in the cleaned data.
Some of the problems faced by businesses across domains are mentioned below:
| Domain | Tasks Affected | Reason |
| Financial Services | Know Your Customer (KYC) | Manually filled Applications |
| Fundamental analysis | Duplicate Filings | |
| Retail eCommerce | Aggregating item names from different channels | Aggregating item names from different channels |
| Social Science | Census data lineage | Mapping persons & households with previous census data to detect demographic changes. |
| Academics | Plagiarism detection | Duplicate submission |
| Bibliographic Deduplication | Ambiguity in author name across citation formats |
While working on an AdTech product, I encountered similar situations with even greater complexities. The metadata and attributes were not consistent across records from different domains. We had to deduplicate entities that had only a name without any supporting attributes. While I can’t discuss the details of the proprietary datasets and algorithms used, I can share our experience with data variation challenges, analysis patterns, and ways to address open-domain problems.
In this blog, I will focus on the challenges posed by data variation, annotation, and computation, as well as how openly accessible tools can assist in solving some of these challenges. In Part 2, I will delve into a more effective solution that achieves 95% accuracy in identifying duplicate records using AI.
Using AI to Solve Duplication Issues
AI algorithms can solve this duplication conundrum and rescue businesses.
But first, let’s clarify the problem statement. Our goal is to map all variations of company names with the same meanings and identity (duplicate records) to a common key. This key will serve as the primary identifier for a record and all its duplicates.
There are a few open datasets in different domains for building ML-based deduplication models. They include:
- Opensanctions: Person, Company, Security, Address
- OpenAIRE: Article Deduplication (Bibliographic and citation)
- ONC Patient Matching: 1 million patient datasets
- EDGAR: US SEC Filings
We utilized the EDGAR SEC filing dataset available on Kaggle to analyze and demonstrate challenges and possible solutions. EDGAR contains a total of 663,000 records, with 58,700 duplicates. Some of the groups contain quite dissimilar company names.
Let’s begin.
Consider the most common issue: the presence of duplicate records with slight differences in the text, such as misspellings, abbreviations, truncated texts, etc. These discrepancies make it challenging to use spreadsheets to identify duplicates. The names in those records could represent anything, from an organization to a person, product, or any other entity with a name associated.
Data Challenges
In EDGAR SEC filing dataset, we observed some of the name variations such as abbreviations, partial/truncated names, variations in punctuations, replacement with similar words and spelling mistakes. A few examples are listed below:
| Abbreviations | HENNES & MAURITZ ADR vs Hennes & Mauritz AB MCDONALDS CORP, MCDONALDS CORP of DELAWARE |
| Partial names | KOHLS Corp of WISCONSIN , KOHLS Corp, KOHLS ACQUISITION INC AMERICAN SCRAP PROCESSING INC vs SCRAP PROCESSING INC |
| Truncation | ADAMANT TECHNOLOGIES vs ADAMANT DRI PROCESSING & MINERALS GROUP of NEVADA TSB Bank plc vs TSB Banking Group plc/ADR |
| Replacements | PIERRE CORP. of CA, PIERRE FOODS LLC of NORTH CAROLINA, PIERRE FOODS INC of NORTH CAROLINA |
| Similar | ZZ Global LLC vs ZZLL Information Technology, Inc. |
There are some known solutions businesses frequently use to solve this kind of problem.
Known Solutions in Literature
| Strategy | Pros | Cons |
| Manual deduplication (Sorting and grouping) | Small datasets, easy to do. | Infeasible in large, frequently updated databases. |
| Stricter validation in data entry & ETL | Works for structures data | Not good for unstructured data. Need many custom rules to make it work. |
| Algorithmic deduplication with Human in Loop | No custom rules are required, scalable to large dataset | Requires high domain knowledge for building accurate models |
In a realistic scenario where the data is large, unstructured, and contains numerous variations, we must rely on algorithmic methods to achieve high accuracy with minimal effort in the deduplication process.
Let’s examine the available solutions in the market that we have tried. In the latter half of the blog, we will concentrate on the algorithmic solutions available in the market and review their pros and cons. Additionally, we will identify the best solutions for the problem statements mentioned by businesses, as discussed earlier.
Opensource rule-based solution
We can start by creating an Opensource rule-based solution to get some naïve accuracy results and create a benchmark. I have mentioned various solutions with pros and cons below.
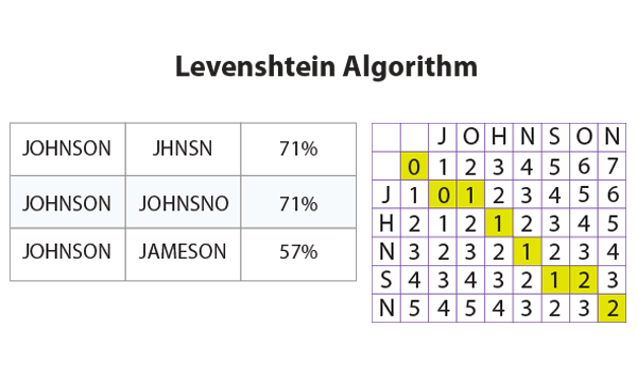
- Fuzzy string matching (Levenshtein, Jaro-Winkler distance)
- Pros: Easier to compute and get started.
- Cons:
- Choosing the right algorithm can be tricky.
- Slight variation in string sequence caused large changes to similarity metrics.
- Computational complexity O(N^2)
- PolyFuzz
- Contains methods like EditDistance, RapidFuzz, TFIDF, and SentenceEmbeddings.
- Pros:
- Many choices of algorithms to map two lists, and group them.
- Similarity measures can be used as features in a custom ML pipeline.
- Cons:
- Performance depends on good cleaning of text.
- Finding a good threshold to use results agreed upon by multiple algorithms is challenging.
- No ML training, only cosine similarity of embeddings
- Search Engine / Inverted Index (Solr / Elasticsearch)
- Pros: Minimal setup cost
- Cons: Poor accuracy due to lack of rich text features for comparison.
- Hashing (LSH)
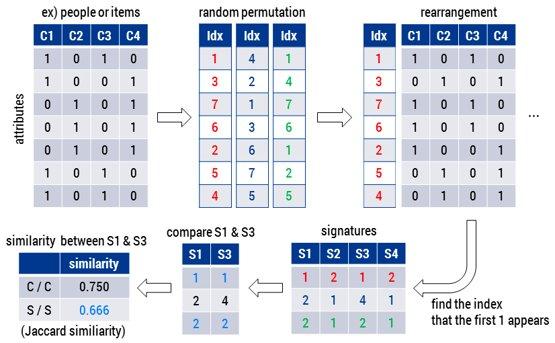
[Source: https://sens.tistory.com/364]
- Pros: Easy to implement based on n-gram hashing,
- Cons: Accuracy is expected to be below 80% due to our prior experience with this technique for server log classification.
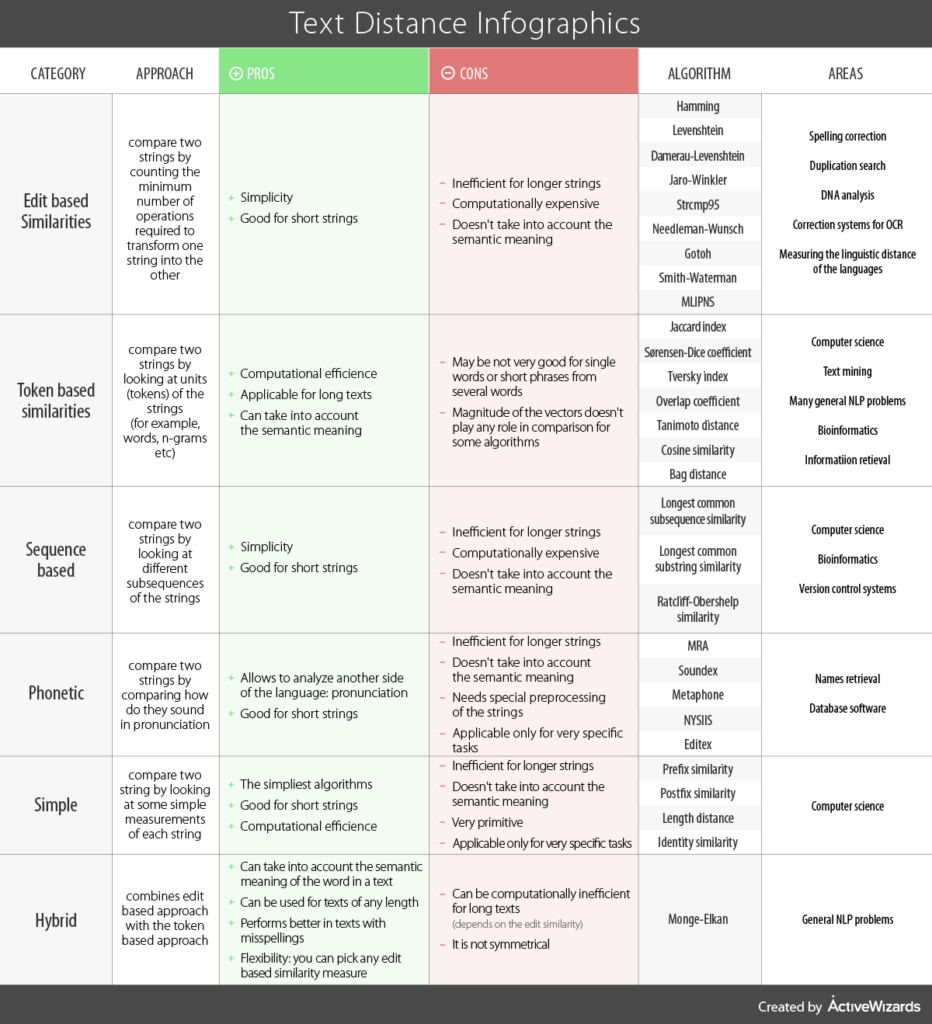
[Source: https://activewizards.com/blog/comparison-of-the-text-distance-metrics]
Opensource rule-based solutions require extensive cleaning and pre-processing of text data due to their reliance on simple similarity thresholds in a few fields. As a result, they are ineffective when applied to unknown test data. You must learn complex dynamic patterns at scale using ML-based solutions to overcome this limitation. Nevertheless, ML training necessitates annotations for each record and group.
Opensource ML-based approaches:
In most cases, we lack the correct reference levels for evaluating and benchmarking the accuracy of ML models. To train ML models, you need effective annotation tools to label data.
For custom data annotation, we can leverage the following opensource annotation tools-
- Active learning to suggest the best pair for annotation.
- Recordlinkage-annotator
- Web-based tool to annotate pairs to be similar/match or distinct.
- DIAL
Let’s discuss a few of the opensource ML-based approaches-
- Company2Vec (Embedding Similarity)
- Company2Vec works at company name only, but finding similar companies requires different cosine similarity thresholds for different name groups.
- Pros:
- Works at company name
- Can be used for generating similar pairs for feature-engineering.
- Embeddings can be used as features.
- Cons
- Finding the right threshold can be challenging and can’t be directly used for grouping.
- Dedupe
It works based on configurable indexing for selecting pairs, generating features using prebuilt components, classifying pairs, and clustering to select group heads.
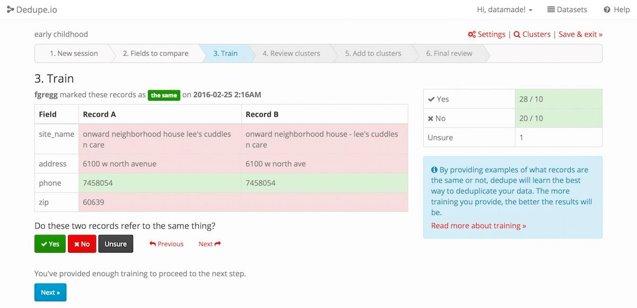
- Pros:
- Allows labeling where the algorithm is making mistakes.
- Can use those annotations to improve in an active learning fashion.
- Its hierarchical clustering-based regrouping function can be helpful in some contexts.
- Cons:
- Requires multiple fields in structured tabular data.
- Data with a single or few columns are difficult to deduplicate.
- Poor performance for Text only field
- Recordlinkage
- It supports indexing/blocking, creating comparison vectors, and classifying pairs using supervised and unsupervised algorithms.
- Pros:
- Useful to descriptively compare if we have multiple fields in our records.
- Better configurable than dedupe.
- Components, like Sorted Neighborhood-based blocking for pair generation, can be used independently.
- Cons:
- Feature generation is not robust for text-only fields.
- Deepmatcher
- Performs blocking, sampling, labeling and matching to obtain matching tuple pairs from two tables.
- Uses attribute embedding, Attribute similarity with comparator or aggregator, and classifiers in the pipeline.
- Extension of Magellan (pyentity-matching) ecosystem.
- Ditto
- Pre-trained Language Model-based entity matching.
- Can incorporate domain knowledge.
- Data-driven blocking and matching with various augmentations.
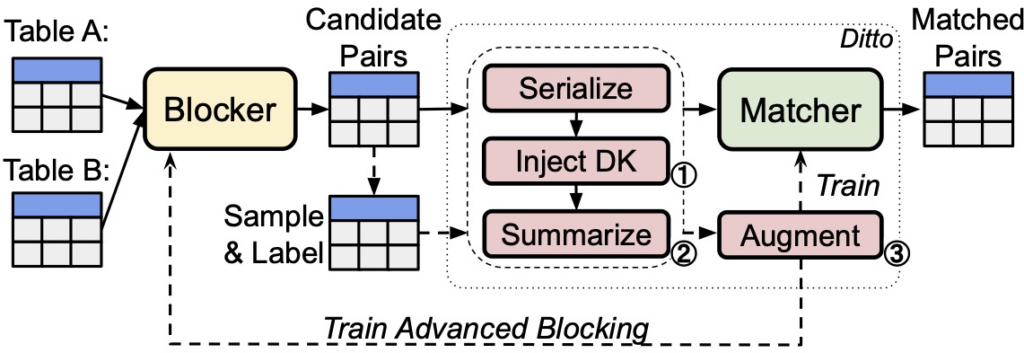
Dedupe and RecordLinkage packages operate based on a pipeline similar to the one depicted below, though the components of each step vary between the two packages.
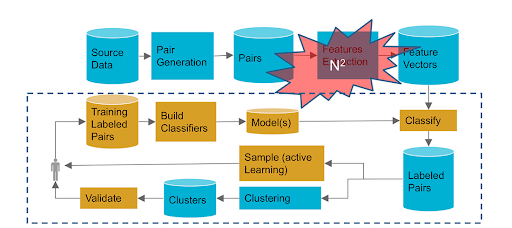
Source: https://wp.sigmod.org/?p=2288
These tools are designed for tabular datasets with multiple fields in them. These are not specialized with domains containing a few short text fields like names. Preparing datasets and annotations for these tools can also be a challenge.
Problem – Solution: Mapping the Right Match
Based on the pros and cons discussed above for different tools and methods, we can select the right method/tool for the right job as mentioned below:
| Domain | Task | Most Effective Tool / Algorithm | Reason |
| Financial Services | Know Your Customer (KYC) | Use Dedupe for visual and Recordlinkage for programmatic clean-ups | Can use both textual description and image features |
| Fundamental Analysis | Heuristic / ML based | Can use supporting description text | |
| Retail & eCommerce | Catalog management | Use heuristic feature matching or Deep learning-based algorithms | Can use both textual description and image features |
| Academic | Plagiarism Detection | Heuristic (hashing), Language Models | Large text for comparison |
| Bibliographic Deduplication | ML Based Approaches | Requires complex feature engineering |
Final Words
In this blog, we have discussed the challenges and impacts of duplicate data on businesses.
- Explored a few heuristic-based solutions and delved into why these may not effectively address complex cases.
- Discussed how heuristic groups can be used for manual annotation prompts.
- Reviewed several other annotation tools that can be leveraged based on their suitability.
- Examined the suitability of a few open-source ML-based solutions for grouping name-like texts. Each of these solutions has its own merits and challenges but may not be able to address all the challenges we encounter.
In the next blog in this series, we will delve into hands-on applications of the techniques we discussed and provide an analysis of the results and any mismatches.
References
https://towardsdatascience.com/string-matching-with-bert-tf-idf-and-more-274bb3a95136
A Record Linkage-Based Data Deduplication Framework with DataCleaner Extension
An End-to-End Big Data Deduplication Framework based on Online Continuous Learning
Matching Algorithms: Fundamentals, Applications and Challenges









