


Introduction
Many startups would like to incorporate a machine learning component into their product(s). Most of these products are unique in terms of the business, the data that is required to train the machine learning models, and the data that can be collected. One of the main challenges that these startups have is the availability of data specific to their business problem. Unfortunately, the quality of the machine learning algorithms is dependent on the quality of the domain specific data that is used to train these models. Generic data sets are not useful for the unique problems that these startups are solving. As a result, they cannot rollout a feature involving machine learning until they can collect enough data. On the other hand, customers ask for the product feature before their usage can generate the required data. In such a situation, one needs to rollout a machine learning solution incrementally. For this to happen, there must be a synergy between the data and the algorithms that have the ability to process this data. To enforce this synergy, we propose a computational model that we refer to as “Data Fingerprinting”.
Algorithms define data requirements
Despite the prevailing belief that data enforces algorithm requirements, or data comes before the algorithm, we take a counter pose and say that it is the algorithms that define the data requirement. We believe that this counter pose lays down the objectives that guide the algorithm developers to incrementally rollout a product feature, which also steadily evolves in its complexity.
The strategy
In this strategy, we:
- Define a product feature
- Build an algorithm that enables this feature
- Determine what type of data can be handled by the algorithm
- Decide to process only data that the algorithm can process
Once the product feature is built, a more complex algorithm is added to the feature and the data goals are re-defined. The idea is to define a simple algorithm to start with, such that, with limited data and unsupervised learning or semi-supervised learning, one inches towards a more complex algorithm. In the process, we computationally control the nature of data so that the data is algorithm-friendly. Having said that, this strategy works only when we design the problem to take advantage of such a strategy.
An Example
Let us work through this strategy using an example. For the sake of this discussion we consider a text understanding system. Nevertheless, the system can be generalized to other objectives that may involve image processing, object recognition etc.
Consider Figure 1. It is a system that takes a natural language input, interprets the input, transforms the input into an intermediate form, and converts the intermediate form into SQL to be executed on a database. The result of the database query is returned back to the user. The system could be a question answering system, a search engine, or a bot that executes a task based on the input text. One can imagine that inputs can be of various forms and complexities like questions, statements, phrases, or just terms. Converting these various inputs to multiple goals latent in the natural language input can get very complex. One might not wait to build a system that solves all the problems before the system can be rolled out to potential customers.

Figure 1: Simple Text Processing Objective
In this scenario, the goal can be simplified and worked backwards. For example, imagine the input text to be the following questions:
- How many students are in the machine learning class?
- How many buses are plying in Mumbai?
One can write these questions as SQL queries as following:
- SELECT COUNT(students) from CLASS_TABLE where COURSE = “machine learning”
- SELECT COUNT(buses) from SCHEDULE_TABLE WHERE status = “plying” and place = “Mumbai”
SQL, being structured can involve very complex queries that the system may not be designed to handle currently. Perhaps, the data to respond to certain queries has not been generated/collected yet. Alternatively, the interpretation logic written by algorithm developers may currently be incapable of converting certain styles of natural language queries into an accurate SQL query. In some cases, certain inputs could be converted to a wrong SQL query, because the logic to process such inputs has not been refined yet. Would we wait till we have a system that can interpret and convert all kinds of input into SQL queries, or would we want to gracefully ignore input that cannot be converted to SQL as yet? One could prefer the latter approach for incremental rollout of the product feature.
A better way to understand this complexity is by visually inspecting the parse trees for the queries we just discussed. Figure 2 and Figure 3 show the parse trees for the two questions mentioned earlier. Note how the trees are similar in structure.
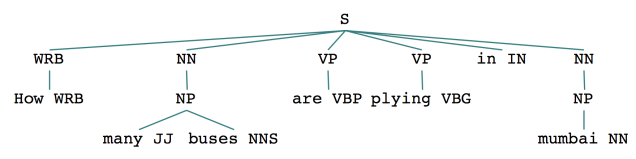
Figure 2: Parse tree for “How many students are in the machine learning class?”
Figure 3: Parse tree for “How many buses are plying in Mumbai?”
Now, let us consider a modification to one of the questions and see what happens to the parse tree:
- How many buses are plying on a route originating at Mumbai and ending at Bangalore?
The SQL query is much more complex for this question and the logic that interprets this new input also needs to handle a more complex structure as is apparent from the parse tree in Figure 4.

Figure 4: Parse tree for “How many buses are plying on a route originating at Mumbai and ending at Bangalore?”
From these simple examples, one can observe that the input data has a latent domain specific structure that varies in complexity based on the data. This also means a pattern for this latent structure can be extracted and used as a representation of the input data. We refer to this pattern as the data fingerprint.
Enforcing Synergy between Data and Computational Capability
To handle variations in input complexity in the context of the processing capability, we can use a pattern recognition system that detects if the input data qualifies to be interpretable by an underlying processing system. In other words, “Is the input data conformant to an objective/algorithm or Does the input data have a known fingerprint?” We refer to this system that enforces synergy between data and the underlying algorithm as the Data Fingerprint recognizer. Figure 5 shows how the processing flow is modified due to the presence of the data fingerprint recognizer.
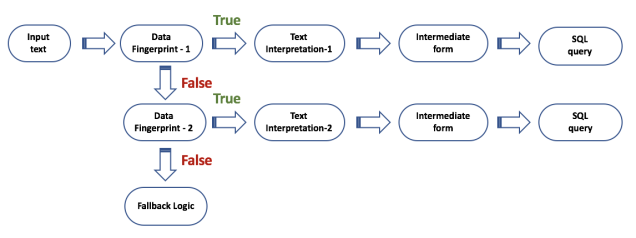
Figure 5: Using a data fingerprint recognizer to introduce incremental complexity
Data Fingerprint
Data fingerprint is a pattern recognition engine that recognizes certain classes of data in the context of the underlying processing logic/algorithm. On recognizing the required type of data, the system gates the input to the algorithm or any other downstream system. If the fingerprint of the input data cannot be recognized, a default logic bypassing the main logic is invoked. It is desirable that the fingerprint generation system be able to transform the input data into a fingerprint irrespective of the type of data. In reality, this is not achievable unless we have data specific processing logic before the data can be transformed into a fingerprint. For example, if the input data is text we need a text processing module that converts text into a standard form. If we have images as the input data, we need an image processing module that converts images into a standard form. A second requirement for the fingerprint system is to be able to incrementally evolve based on the evolution of the underlying algorithm complexity. Figure 5 shows how the data fingerprint system is chained to trigger two separate processing pipelines based on the recognition of input data.
Summary
In this article, we proposed a framework to incrementally introduce machine learning complexity into a data-driven decision-making system. We argued that algorithms dictate data requirements instead of data dictating algorithm requirements. The need for data fingerprinting system as an enforcer of synergy between data and algorithms was introduced in a text processing context.
In subsequent articles, we shall describe how the data fingerprint system can be implemented with specific downstream data processing applications in mind. We will describe how the system was implemented using a class of Neural Networks popularly referred to as auto-encoders. We will be describing the system in the context of text and image processing applications and will present an evaluation of the accuracy of the fingerprinting system.








