

With the growing rate of data in the IT industry, the requirement of structuring, and processing data has also increased subsequently in the last 10 years. Performing analytical processing is another big tide in the ocean of information. Considering this scope, most of the cloud providers have already provided many data warehousing, data lake, and data analytics platforms as SaaS.
But having the platforms alone isn’t enough, as shipping the data to the platform is another major task. Shipping the data to the data processing takes an equal amount of effort as processing analytics to compute operations. Stitch-data provides a cloud-based ETL pipeline for performing continuous replication of data from multiple sources to your preferred data analytics platform.
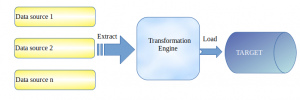
Image 1- ETL Pipeline flow
ETL stands for Extract Transform Load, referring to a set of processes extracting data from an input source, transforming the data, and loading into an output destination such as a database, data mart, or a data warehouse for reporting, analysis, and data synchronization.
Extract: This step refers to the collection of data from various heterogeneous sources such as business systems, APIs, sensor data, marketing tools, and transaction databases, among others. Most of the popular data sources provide structured data whereas others provide semi-structured JSON output. This can be a triggered replication based on some factors or events or can be an asynchronous replication.
Transform: The second step consists in transforming the data into a format that can be used by different applications. This could mean a change from the format the data is stored into the format needed by the application that will use the data. Successful extraction converts data into a single format for standardized processing. There are few tools that assist in achieving this transformation, such as DataStage, Informatica, or SQL Server Integration Services (SSIS).
Load– Finally the information which is now available in a consistent format gets loaded. This data is then written on the expected target platform and ready to perform the analytics and data aggregation.
ETL with the Use of Stitch
Stitch is a cloud-based ETL data pipeline service, which does the bull work of data detection, fetching, and loading the transformation engine with continuous replication.
Including the transformation itself, there are two main components in Stitch, Integration and Destinations which resemble the input sources and targets respectively. Being a managed service, stitch has its platform hosted at https://stitchdata.com where initial Signup is required. Signing Up for a free account is really easy using your mail ID without any complex verification process. Once signed in, you are asked to add integration and then a destination. That’s it! Your pipeline is ready.
Image 2- Stitch Data landing page.
Integration
Stitch provides a platform to collate data from various data sources to a single destination, also called as integrations. These integrations are broadly classified as SaaS, Databases, Webhooks, and some custom integrations.
Continuous replication of data after configuring the Integration is achieved either by pushing to Stitch via API or webhook or pulled on a schedule by the Singer-based replication engine. Once data is accepted, it is passed through Clojure web service import API in form of JSON where a validation check and an authorization check are done before writing the data to a central Apache Kafka queue. The Apache Kafka server is replicated across 3 different data centers for high availability and data is made available only if it is replicated in either of two data centers.
Usually, data is read off of the queue within seconds by the Streamery which is a multithreaded Clojure application that writes the data to files on S3 in batches, separated based on its destination and database tables.
The next section talks about a list of highly-popular supported integrations-
Highly Popular SaaS Integrations
- Salesforce
- Github
- GitLab
- Google Ads
- Google Sheets
- Harvest
- Hubspot
- LinkedIn Ads
- MailChimp
- Microsoft Advertising
- Quickbooks
- Shippo
- Trello
- Zendesk
Popular Databases
- Aurora MySQL RDS
- Aurora PostgresSQL RDS
- Amazon Oracle RDS
- Amazon S3 CSV
- Google CloudSQL MySQL
- Heroku
- Magento
- MariaDB
- Microsoft SQL Server
- Microsoft Azure SQL Database
- MongoDB
- SFTP
Webhook Integrations
- AfterShip
- Incoming Webhooks
- Send Grid
- SparkPost
- Zapier
Discover all integrations here, and also, suggestions are welcomed on “Suggest an Integration” Tab.
Transformation
As described in the integration step, once data is loaded in S3, it is further sent to Spool queue service which is consumed by Loader, which is another service by Closure for performing conversion process of data to the format compatible by the destination.
Every destination (described next) has a different data type, and requires separate pre-processing. The architecture is designed is a way that every processing has an isolated environment and scaling configured, as each processing unit can be scaled as per the increased rate of consumption and in case of disaster, rest of the services are not hampered.
Destinations
After configuring Integrations, the data starts getting replicated in the Stitch pipeline, and then it is time to load the data in target destinations after transformation is complete. At this moment, Stitch supports the following destinations:
- Amazon Redshift
- Amazon S3
- Google BigQuery(v1)
- Google BigQuery(v2)
- Microsoft Azure SQL Data Warehouse
- Panoply
- PostgresSQL
- Snowflake
- world
Above destinations can easily be switched if you want to change the destination used initially considering the new destination is already configured.
Example:
One of the pipeline integration I tried was using AWS Aurora MySQL RDS as integration and Google Cloud Big Query as a data analytics platform.
After completing the signup at https://stitchdata.com next step is to add the integrations. Integrating any data source to Stitch pipeline is very straight forward by following the Stitch official documentation. For the above MySQL integration, documentation is available on stitch website here which can be referred for the configuration steps required to provide the DB access for stitch users.
Many more sources are available with all the required documentation here which can be explored based on the business requirement. MySQL sample database looks something like this once configuration is completed.
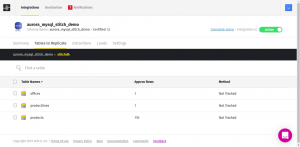
Image 3- Successful integration of MySQL with stitch.
Once the data is in stitch, it’s time to get the destination ready and choose the BigQuery destination on the landing page.
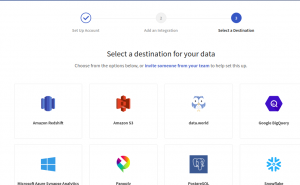
Image 4- Destination landing page.
Big Query platform in Google cloud needs to be accessed by stitch, so here is the simple instruction to create an IAM role-based access in GCP console.
Image 5- Successful Big query Destination configured.
Conclusion:
Now, instead of managing the data shipping, continuous data replication, and data transformation, users can focus on performing analysis of data fully. Just configure the stitch pipeline and it will do the rest. Support for multiple integrations will create a very efficient pipeline converting multiple data formats to a single compatible format for processing.




