

Context
Data center networks every so often use compactly interconnected topologies to deliver high bandwidth for internal data exchange. In such network, it is precarious to employ effective load balancing schemes so that all the available bandwidth resources can be utilized. In order to utilize all the available bandwidth traffic need to be routed across the network instead of overloading a single path. Equal Cost Multipath (ECMP) enable the usage of multiple equal cost paths from the source node to the destination node in the network. The advantage of using this algorithm is that the traffic can be split more uniformly to the whole network avoiding congestion and increasing bandwidth consumption.
This blog explains hash based ecmp load balancing algorithm.
Background
ECMP load balancing refers to distributing traffic more evenly by installing entries for multiple best paths to the switch’s forwarding layer and using load balancing algorithm to identify flows and distribute them to different paths. If number of flows is large this algorithm helps in distributing the traffic along with other unused paths in order to reduce the congestion. ECMP implementation enables us to evenly spread flows across the network leading to best utilization of multiple links towards the destination. It reduces the time taken in data transfer up to large extent due to less congestion. This algorithm helps us in improving network performance in SDN enabled networks.
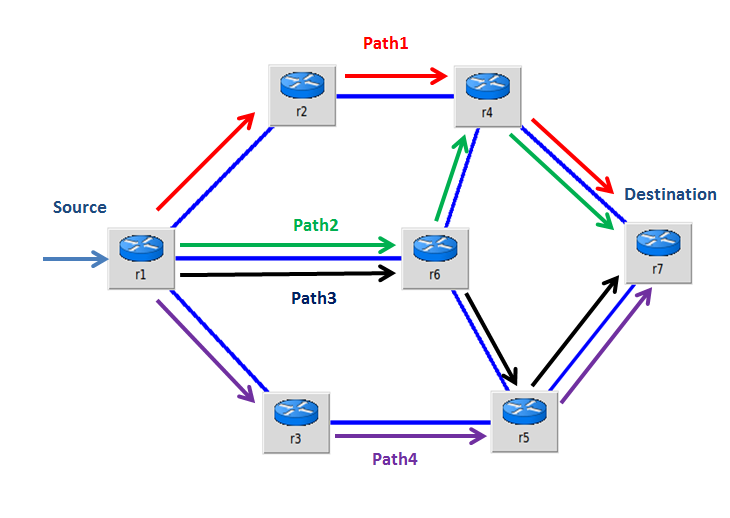
An example of ECMP load balancing is shown above. Here four equal cost paths are available to route the packet to destination. With use of ECMP algorithm all four paths are getting utilized to route packets. This helps in distributing traffic evenly across the network and reduces congestion. Additionally, these four ECMP paths are backups for each other. If one of the paths fails, traffic could be split between the other three paths after failure detection.
Load balancing algorithm
ECMP implementation ensures, if there are numerous best paths to get to a specific MAC
address (i.e. multiple paths have the same cost metric), the controller installs rules in switches in such a way so that all the paths to reach that MAC address are utilized instead of overloading a single path. This is accomplished by identifying rules that match on more fields in conjunction with the destination MAC address. This algorithm finds all possible shortest paths to reach the destination and perform modulus operation on the hash value with number of shortest possible routes and select the final path based on the output. Once final path is decided controller installs the rule on all switches of selected path and forwards the packet to destination host.
This implementation has been categorized into two steps.
1. Multiple best path selection algorithm
When the first packet of a flow arrives on source switch it forwards the packet to SDN
controller as switch does not have rules that match with it. The controller then checks to see what could be the possible ways to reach the packet’s destination MAC address. First it tries to figure out the destination switch from which destination host is connected. We are
populating a dictionary where key is host’s MAC address and value is a tuple consisting of
switch and port with which host is connected. The Controller looks up in this dictionary to get the destination switch
- If destination MAC address entry is updated : It gets the respective switch and the
port on which destination is connected. If source switch and destination switch both are same then controller simply installs the rule to forward the packet on out port as there is only one possible path to reach the destination. If source switch and destination switch both are different we try to get all possible shortest paths to reach the destination using Dijkstra algorithm. We did slight modification in Dijkstra algorithm to get multiple shortest paths between source and destination instead of a single path. Topology information is represented as non directional
graph and stored as an adjacency list. All edges have equal cost. This algorithm computes the weight of the path where weight of the path is sum of weight of constituent edges and returns paths with minimum weightage. This gives us all possible shortest path to reach the destination.
Here is the algorithm to compute all shortest path from source to destination.
def get_all_paths(self,graph,src):
'''gets adjacent nodes of source'''
self.topodict = deepcopy(graph)
length = len(self.topodict)
type_ = type(self.topodict)
nodes = self.topodict.keys()
pdb.set_trace()
visited = [src]
path = {src:{src:[]}}
nodes.remove(src)
distance_graph = {src:0}
pre = next = src
paths = {}
while nodes:
distance = float('inf')
for v in visited:
pdb.set_trace()
for d in nodes:
if d in self.topodict[v].keys():
new_dist = self.topodict[src][v] + self.topodict[v][d]
if new_dist < distance:
distance = new_dist
next = d
pre = v
self.topodict[src][d] = new_dist
path[src][next] = [pre]
elif new_dist == distance:
if not d in path[src].keys():
path[src][d] = []
path[src][d].append(v)
distance_graph[next] = distance
visited.append(next)
nodes.remove(next)
return path
- If destination MAC address entry is not updated: In that case it send the packet out
on all ports except the one it came in and learns the location of the hosts.
We populate dictionary with this entry so that next time when packet for that destination arrives instead of flooding all ports we can just send to the appropriate port. This is based on backward learning concept. Next packet in the flow will follow the above mentioned logic and ECMP forwarding rule will be installed for the flow.
2. Hashed Routing
When forwarding a packet the switch must decide which path to use. Fundamentally, <n>
paths exist in the forward and reverse path direction for given source and destination.
In hashed routing a modulo <n> hash of various header information is performed. Header
fields used for hash calculation includes source IP address, destination IP address, protocol, Source port and Destination port. Hash function returns ECMPstyle
5 tuple hash for packets, otherwise 0. We perform modulus operation on the hash value with total number of best possible routes. The output of this modulus indicates which of the paths to use.
Header fields
{
hash_input[0] = ip.srcip
hash_input[1] = ip.dstip
hash_input[2] = ip.protocol
hash_input[3] = source port
hash_input[4] = destination port
}
Ideally, the header information and hash algorithm are chosen such that an arbitrary traffic pattern will be equally distributed on the paths while ensuring that a single flow remains on the same path for the life of the flow in order to preserve inorder
packet delivery.
This algorithm has been depicted well with flow diagram shown below.
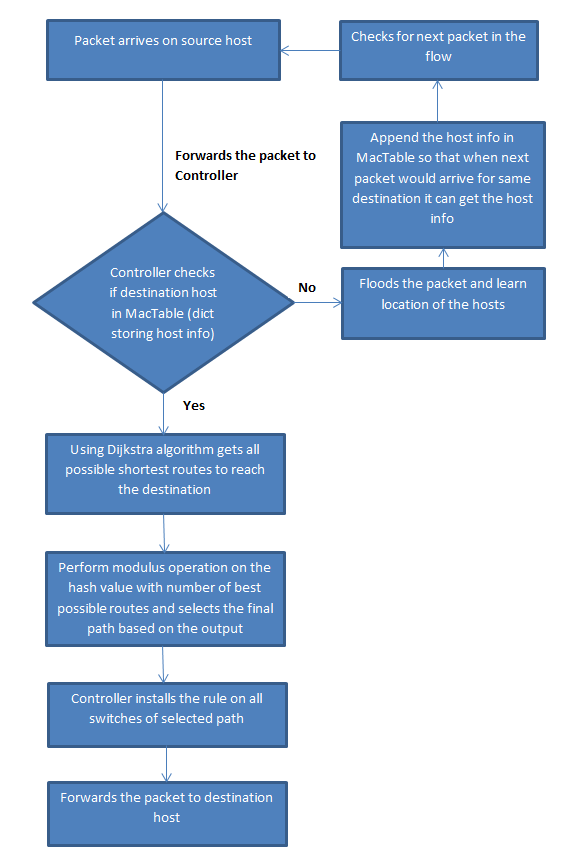
This algorithm helps in reducing congestion in network. Due to less congestion it would also help in reducing the time taken in data transfer. Also with use of this algorithm network performance of shuffle phase data transfers in Hadoop MapReduce can be enhanced.








